How Uber Serves over 40 Million Reads per Second with Caching
We'll talk about Uber's caching system. Plus, Jeff Dean's talk on trends in ML, common ways to implement retries and Andrej Karpathy's lecture on building the GPT tokenizer
Hey Everyone!
Today we’ll be talking about
How Uber Serves over 40 Million Reads per Second with Caching
For Uber’s storage needs, they built Docstore, a distributed database that stores petabytes of data and serves millions of requests per second
An issue with Docstore was that it didn’t have an integrated caching layer. Instead, individual teams at Uber were implementing their own caching
Uber Engineering published a blog post on how they added a caching layer to Docstore
It’s built on Redis and serves over 40 million requests per second across all Docstore instances
We’ll delve into how Uber tackled problems like cache invalidation, warming, timeouts and more
Tech Snippets
Building the GPT Tokenizer by Andrej Karpathy
Common Ways to Implement Retries
Exciting Trends in Machine Learning by Jeff Dean
Erlang Concepts Explained
How Uber Serves Over 40 Million Reads Per Second with Caching
Uber is the world’s largest rideshare company with over 25 million trips completed every day. The company is still growing quite quickly, with 24% year-over-year growth in the number of trips completed.
The stock price has nearly quadrupled over the past two years going from a low of $21 to an all-time high of $76… so Uber engineers are probably pretty happy with their stock-comp right now.
On the other hand, all this growth unfortunately leads to scaling pains.
Docstore is an in-house, distributed database that Uber has built on top of MySQL. They use it to store petabytes of data and it serves tens of millions of requests per second. All of Uber’s business verticals rely on Docstore for storage. To read more about Docstore, I’d recommend checking out this blog post from Uber Engineering.
One issue with Docstore is that it didn’t have a separate layer for caching commonly requested data.
Instead, individual teams at Uber were maintaining their own Redis caches for their specific microservice. They were each implementing their own caching logic and this led to an inefficient use of engineering time.
Therefore, the Docstore team at Uber decided to build CacheFront, a caching layer for Docstore.
Uber Engineering published a fantastic article on CacheFront that you can check out here.
We’ll be summarizing the article contents below.
Goals of CacheFront
Here’s the targets that the Uber team had when they set out to build a caching layer for Docstore
Organizational Efficiency - each team at Uber shouldn’t have to implement their own caching logic in their microservice. Docstore should handle caching for everyone.
Decoupling - the caching layer should be detached from Docstore’s sharding scheme in the storage engine layer. That’ll avoid future headaches that can come from hot keys/shards.
Scalability - the caching layer should help Docstore handle a higher read/write load without having to massively increase the amount of compute in the MySQL layer.
Latency - adding the caching layer should improve P50 and P99 latencies. It should also help stabilize read latency spikes when there are bursts in traffic.
CacheFront Architecture
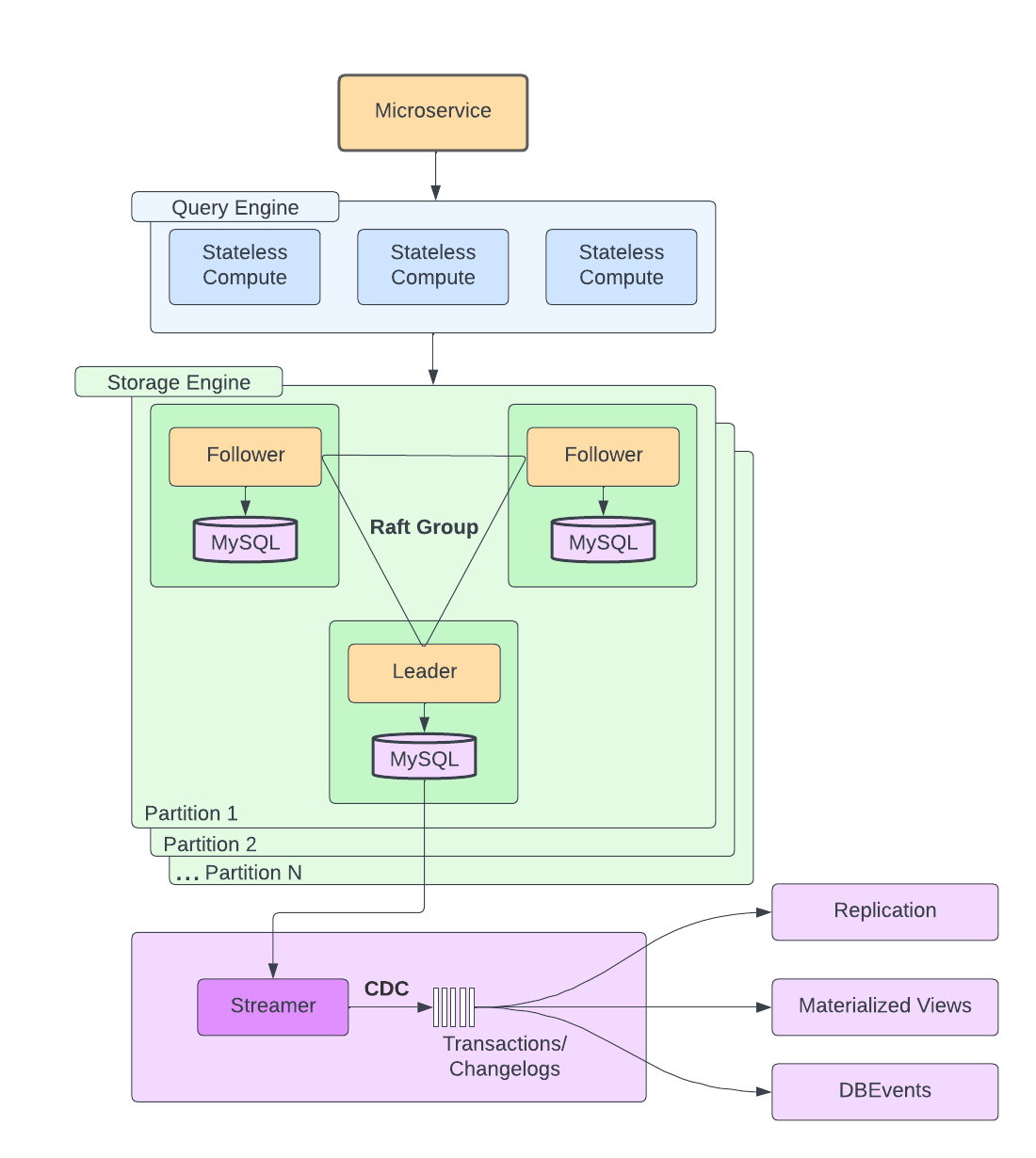
Original Docstore Architecture
When you send a read/write to Docstore, that first goes to the database’s query engine layer. This layer is responsible for figuring out how to route the query to the different underlying storage nodes in the most efficient way.
The storage engine layer consists of the MySQL nodes and handles things like answering queries from the query engine layer, replicating data between MySQL nodes, handling transactions and more.
In order to add an integrated cache, Uber modified the query engine layer to also check an additional caching layer. This caching layer is built on top of Redis and uses a cache-aside strategy.
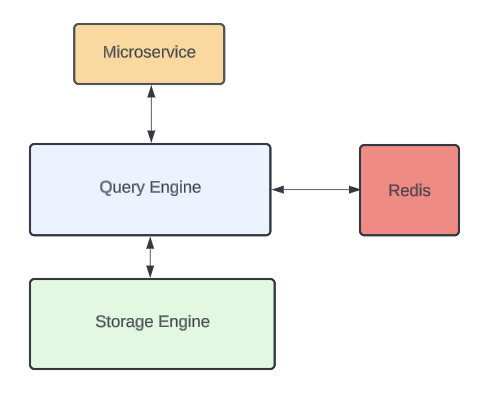
Docstore with a Redis Caching Layer
With cache-aside, the query engine will first try getting requested data from the caching layer (Redis). If there’s data that isn’t in the cache, then it will query the storage engine layer.
After responding to the user with all the data, the query engine layer will asynchronously populate the caching layer with that data (so it’ll be a cache hit the next time a user requests it).
With any caching strategy, there’s certain problems that you’ll have to address.
You have to take care of things like
Cache Invalidation
Cache Warming
Handling Outages
We’ll talk about all the problems the Uber team had to address and how they dealt with them.
Cache Invalidation
When key-value pairs are stored in Redis, Uber sets a configured TTL (by default, 5 minutes). When the TTL expires, the key-value pair is removed from the cache.
However, what if there’s a new write in Docstore that changes the value associated with that key-value pair. How do you update the cache?
To do this, Uber uses CDC (change data capture) based on the MySQL binlog. Whenever there’s a data update, Uber will take the change (and its associated timestamp) and check if there should be any modification to a cached value in Redis.
With this, they’re able to make the cache consistent within seconds of a database change, as opposed to minutes.
Measuring Cache Freshness
In order to keep track of how up-to-date the data in the cache is (minimize stale data), Uber added a shadow mode to the query engine.
When this mode is enabled, reads will go to both the storage engine layer and the caching layer. Then, they compare the cached data with the source-of-truth (storage engine layer) and check if there are any mismatches.
With their shadow mode, they’ve been able to find that the cache is 99.99% consistent.
Cache Warming
Uber has multiple instances of Docstore set up in an active-active configuration to minimize downtime. If one of the instances of Docstore goes down then the other instance will immediately step in.
The issue with this is that if the cached values from the original Docstore instance aren’t stored in the new instance then there will be a spike in cache misses (leading to a big increase in latency and database load).
Uber solves this with cache warming. When a value is cached in a certain Docstore instance, that Redis write gets sent to all the other Docstore instances’ caching layers for replication.
Circuit Breakers
If a Redis node goes down, then sending additional requests to it will add unnecessary latency to Docstore (since it’s a guaranteed cache miss).
Therefore, the team wanted to implement a circuit breaker that will cut off requests to Redis nodes with a high error rate.
To do this, they use a sliding window circuit breaker. They count the number of errors on each node per time bucket and compute the number of errors in the sliding window width.
If it passes a certain threshold, then no more requests can be made to that Redis node until the sliding window passes.
Adaptive Timeouts
One issue that came up was setting the right timeouts for Redis operations. If the timeout is too short, then you might cut-off a Redis operation that is in the process of executing (wasting both Redis resources and query engine layer resources).
On the other hand, if the timeout is too long, then that’ll negatively affect your P99.9 and P99.99 latencies (the latency of the slowest 0.001% and 0.0001% of requests).
Instead, the team configured adaptive timeouts that increase and decrease dynamically. They keep track of the get/set latencies and set the timeout to be equivalent to the P99.99 latency of cache requests (the timeout will get triggered when the request takes longer than 99.99% of requests).
This way, the remaining 0.0001% of requests (that are taking too long) will just be served by the storage engine layer.
Results
Here’s some of the results that Uber saw from adding the caching layer to Docstore
Latency - Docstore latencies have decreased significantly with P75 latency down 75% and P99.9 latency down 67%.
Scalability - The caching layer is scalable and fault tolerant. One of Uber’s largest initial use cases drove over 6 million requests per second and had a 99% cache hit rate.
Efficiency - If Uber didn’t add the cache, they would’ve had to add nearly 60,000 CPU cores in order to serve that 6 million requests per second from the storage engine directly. By adding the caching layer, they were able to serve those requests with only 3,000 Redis cores.
CacheFront supports over 40 million requests per second across all Docstore instances.
For more details, read the full article here.


