How Uber Optimized their Hadoop Clusters
Uber runs one of the largest HDFS clusters in the world. We'll talk about an issue they faced and how they solved it. Plus, principles from Atomic Habits and how you can get better at giving feedback
Arpan KG
March 27, 2024
Hey Everyone!
Today we’ll be talking about
How Uber uses HDFS - Uber runs one of the world’s largest HDFS clusters with exabytes of data and thousands of nodes. We’ll delve into scaling issues they faced and the solutions they came up with.
Introduction to Hadoop Distributed File System and it’s Architecture
Details about Uber’s HDFS clusters
Issues with Data Skew from HDFS Balancer
Fixing the issue by changing DataNode configuration settings, improving the HDFS Balancer algorithm and adding more Observability
Principles from Atomic Habits - Atomic Habits is an amazing book on how you can build positive habits and get rid of negative ones. It gives a comprehensive framework for behavior change and it’s one of the most impactful books I’ve read.
Make good habits obvious and fun to do
Eliminate any friction in good habits and make them satisfying to do
Invert the “four rules of behavior change” to get rid of bad habits
Tech Snippets
How to Create Good Internal Documentation for your Company
Getting Better at Giving Feedback (for Managers)
How Photoshop works with Files that are Too Large to Fit in Memory
How Netflix tests their code for Regressions
How Uber uses Hadoop Distributed File System
Uber is the largest ride-share company in the world with over 10 billion completed trips in 2023.
They also maintain one of the largest HDFS (Hadoop Distributed File System) deployments in the world, storing exabytes of data across tens of clusters. Their largest HDFS cluster stores hundreds of petabytes and has thousands of nodes.
Operating at this scale introduces numerous challenges. One issue Uber faced was with the HDFS balancer, which is responsible for redistributing data evenly across the DataNodes in a cluster.
We'll first provide a brief overview of HDFS and how it works. Then, we'll explore the issue Uber encountered when scaling their clusters and the solutions they implemented. For more details on Uber’s experience, you can read the blog post they published last week.
If you’d like to remember the concepts we discuss in this article, check out Quastor Pro.
You’ll get detailed Space-Repetition Anki Flash Cards on all the concepts covered in past Quastor Articles. The flash cards cover concepts from load balancing, network protocols, databases and more!
Introduction to HDFS
Apache Hadoop Distributed File System (HDFS) is a distributed file system that can store massive amounts of unstructured data on commodity machines. HDFS serves as a data lake, so it’s commonly used to store unstructured data like log files, images/video content, ML datasets, application binaries or basically anything else.
It’s based on Google File System (GFS), a distributed file store that Google used from the early 2000s until 2010 (it was replaced by Google Colossus).
Some of the design goals of GFS (that HDFS also took inspiration from) were
Highly Scalable - you should easily be able to add storage nodes to increase storage. Files should be split up into small “chunks” and distributed across many servers so that you can store files of arbitrary size in an efficient way.
Cost Effective - The servers in the GFS cluster should be cheap, commodity hardware. You shouldn't spend a fortune on specialized hardware.
Fault Tolerant - The machines are commodity hardware (i.e. crappy) so failures should be expected and the cluster should deal with them automatically. An engineer should not have to wake up if a storage server goes down at 3 am.
The HDFS architecture consists of two main components: NameNodes and DataNodes.
The DataNodes are the worker nodes that are responsible for storing the actual data. HDFS will split files into large blocks (default is 128 megabytes) and distribute these blocks (also called chunks) across the DataNodes. Each chunk is replicated across multiple DataNodes so you don’t lose data if a machine fails.
The NameNodes are responsible for coordination in the HDFS cluster. They keep track of all the files and which file chunks are stored on which DataNodes. If a DataNode fails, the NameNode will detect that and replicate the chunks onto other healthy DataNodes. The NameNode will also keep track of file system metadata like permissions, directory structure and more.
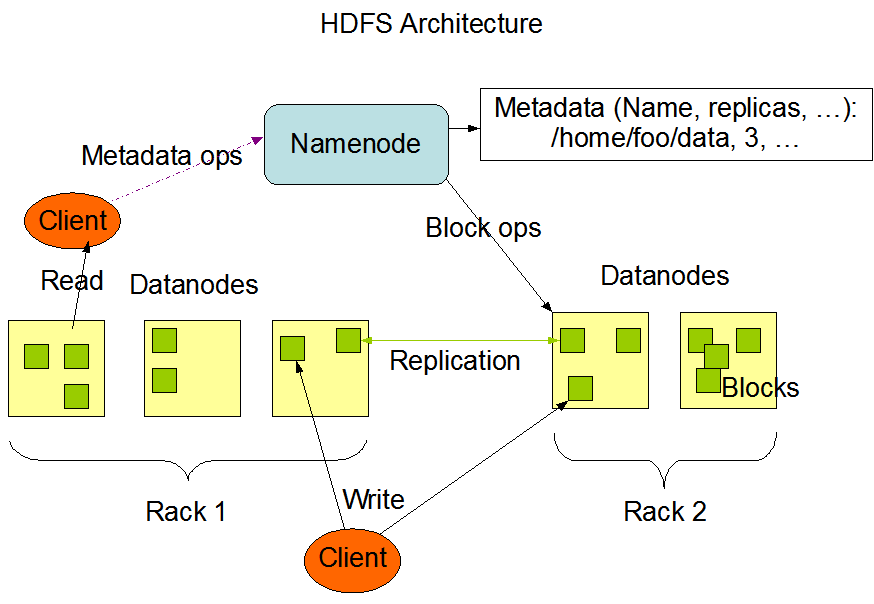
One important tool in the ecosystem is HDFS Balancer. This helps you balance data across all the DataNodes in your HDFS cluster. You’ll want each DataNode to be handling a similar amount of load and avoid any hot/cold DataNodes.
Unfortunately Uber was having issues with HDFS Balancer. We’ll delve into what caused these issues and how they were able to resolve them.
Uber’s Issues with HDFS
HDFS Balancer is meant to evenly distribute the load across all the DataNodes in your cluster. However, it wasn’t working at Uber’s scale (their largest HDFS clusters stored tens of petabytes of data)
Some DataNodes were becoming skewed and storing significantly more data compared to other DataNodes. Thousands of nodes were near 95% disk utilization but newly added nodes were under-utilized.
This was happening because of two reasons
Bursty Write Traffic - When there’s a sudden spike in data writes, HDFS Balancer didn’t have enough time to balance the data distribution effectively. This leads to some nodes receiving a disproportionate amount of data.
Bad Node Decommissions - Uber performs frequent node decommissions for hardware maintenance, software upgrades, cluster rebalancing, and more. When a DataNode is decommissioned, its data is replicated and moved to other available nodes to ensure data availability and redundancy. However, this replication wasn’t efficiently implemented and it was increasing the skew of data across the DataNodes.
This data skew was causing significant problems at Uber. Highly utilized nodes were experiencing increased I/O load which led to slowness and a higher risk of failure. This meant fewer healthy nodes in the cluster and overall performance issues.
Uber solved this through three main ways:
Changing HDFS Configuration Properties
Optimizing HDFS Balancer Algorithm
Adding Increased Observability
We’ll go into all three.
HDFS Configuration Properties Changes
The Uber team modified some of the DataNode and HDFS Balancer configuration properties to help reduce the skew problem.
Some of the properties they changed were:
dfs.datanode.balance.max.concurrent.moves- This determines the maximum number of concurrent block moves allowed per DataNode during the balancing process. Uber increased this so that heavily utilized DataNodes can transfer more data blocks to other nodes simultaneously.dfs.datanode.balance.bandwidthPerSec- This sets the maximum bandwidth (in bytes per second) that each DataNode can use for balancing. Again, Uber increased this so that DataNodes can transfer blocks faster during the balancing process if they're overwhelmed.dfs.balancer.moverThreads- This allows the balancer to spawn more threads for block movement, enhancing parallelism and throughput.
Optimizing HDFS Balancer Algorithm
HDFS Balancer periodically checks the storage utilization of each DataNode and moves data blocks from nodes with higher usage to those with lower usage.
The Uber team made some algorithm improvements to their HDFS balancers to reduce the data skew in the cluster.
Some of the improvements were
Using Percentiles instead of Fixed Thresholds - When looking for lower-utilization nodes, the HDFS Balancer was using fixed thresholds (using less than 30% of disk space for ex.) The issue was that it wasn’t finding enough lower-utilization nodes that met this threshold. The Uber team changed this to use a percentile instead of a fixed threshold (nodes that are in the 35th percentile of disk usage)
Prioritizing Movements to Less-Occupied DataNodes - the original balancing algorithm treated all under-utilized DataNodes equally, without considering their relative utilization levels. Uber modified the algorithm to prioritize moving data to the least-utilized DataNodes first
Observability
Uber also introduced new metrics and a dashboard to better understand the performance of the optimized HDFS balancer. They added more than 10 metrics to help them understand how HDFS Balancer was working and check if any calibrations were needed.
Results
With the optimizations in HDFS balancer, Uber was able to increase cluster utilization from 65% to 85%. All of the DataNodes remained at below 90% usage and they increased throughput in the balancing algorithm by more than 5x.
Tech Snippets


Subscribe to Quastor Pro for long-form articles on concepts in system design and backend engineering.
Past article content includes
System Design Concepts
| Tech Dives
|
When you subscribe, you’ll also get Spaced Repetition (Anki) Flashcards for reviewing all the main concepts discussed in past Quastor articles
Principles from Atomic Habits
Atomic Habits is a fantastic book on behavior change through small changes. If you can change the small habits you have every day (going to the gym instead of watching Netflix, for example), then this will compound to massive changes over months and years.
The book relies on four laws of behavior change.
Make it Obvious
Use obvious cues to trigger your desired habit - Place visual cues in your environment to remind you of the habit you want to build. If you want to play the guitar, then always have your guitar right next to your desk.
Use Implementation Intentions - Plan out exactly when you'll perform your new habit. Be specific. Don't just say, "I'll exercise more." Instead, say, "I'll go for a 30-minute run in the park every Monday, Wednesday, and Friday at 6 pm."
Habit Stacking - Attach your new habit to an existing one. If you go to Starbucks every morning for a coffee, then you might say, "I'll spend 30 minutes at Starbucks every day reading through a technical book while I enjoy my coffee."
Make it Attractive
Associate your habit with positive outcomes - Focus on the benefits of your new habit. If you want to start eating healthier, then focus on how much energy you'll have and how much better you'll feel.
Make it Easy
Simplify the habit by removing obstacles - Reduce any friction that comes with starting the new habit. If you want to eat healthier, then make sure you always have plenty of fruits and vegetables within close reach.
Use the "Two-Minute Rule" to get started - Start with a habit that takes less than two minutes to complete. If you want to start reading more technical books, then start with an initial goal of reading one page per day. Slowly build up to more.
Make it Satisfying
Reward yourself for completing the habit - Give yourself a small reward after completing your habit. This could be a small snack or extra leisure time. The positive reinforcement makes it more likely you'll repeat the habit.
Use social accountability to stay motivated - Find an accountability partner who's working towards a similar goal and share progress with them.
The great thing about these rules is that they’re also effective in stopping negative habits. All you have to do is invert them.
If you want to stop a certain behavior, then you should
Make it Invisible
Reduce exposure to the cues that cause the behavior - If you want to stop eating junk food, remove it from your home.
Make it Unattractive
Reframe your mindset to highlight the benefits of avoiding the behavior - If you want to quit smoking, focus on the health benefits of being a non-smoker (improved athletic performance, healthier skin, etc.).
Make it Difficult
Increase the number of steps between you and the behavior - If you want to reduce time on social media, then delete all the apps from your phone. The extra hassle of having to re-download the apps helps limit usage.
Make it Unsatisfying
Create a habit contract - Make a formal agreement with a friend that includes consequences for engaging in the undesired behavior. If you want to stop smoking, then you could agree to donate a certain amount of money to a cause you don't support each time you smoke.
These are a couple of the tips from Atomic Habits. I’d highly recommend checking the book out if you’d like to learn more.