How Uber Minimizes Flaky Tests
We'll delve into the architecture of Testopedia, a service Uber uses to find and eliminate flaky tests. Plus, job market insights from Hacker News, switching to engineering management and more.
Arpan KG
July 05, 2024
Hey Everyone!
Today we’ll be talking about
How Uber Minimizes Flaky Tests
For every code diff, Uber has to run 10k+ tests on average. A key challenge is to make sure these tests are reliable and don’t fail due to errors unrelated to the code.
Uber wrote a great blog post delving into how they ensure this with Testopedia, a service that analyzes test statistics around staleness, reliability, latency, etc.
We’ll talk about the architecture of Testopedia and how they manage/treat flaky tests.
Tech Snippets
Insights from over 10,000 comments on Hacker News’ Hiring Threads
Programming advice I’d give to myself 15 Years Ago
Why clever code is probably the worst code you could write
Switching from a Software Engineer to Engineering Manager
How Uber Minimizes Flaky Tests with Testopedia
Uber has an enormous engineering team with over 5,000 developers. On a typical day, they contribute 2,500+ pull requests with features, bug fixes, rewrites, etc.
For each pull request, Uber needs to run over 10,000+ tests. This helps them ensure that their master branch is always green (able to compile and execute).
However, running all these tests can quickly hurt developer productivity if they don’t make sure that the tests are reliable (accurately failing/succeeding without flaky behavior) and performant (low latency).
To handle this, Uber built Testopedia, a system that sits within their CI infrastructure and takes care of
Generating and Storing Test Statistics - keep track of individual test stats around staleness, reliability, historical runs, execution time, etc.
Retrieve Test Statistics - retrieve the statistics for a test case (or a group of test cases).
Notifying Teams for Bad Tests - whenever a test becomes unhealthy, Testopedia can create a JIRA ticket and assign it to the relevant team.
In this article, we’ll delve into some interesting problems Uber engineers faced when building Testopedia and how they solved them.
Testopedia Architecture
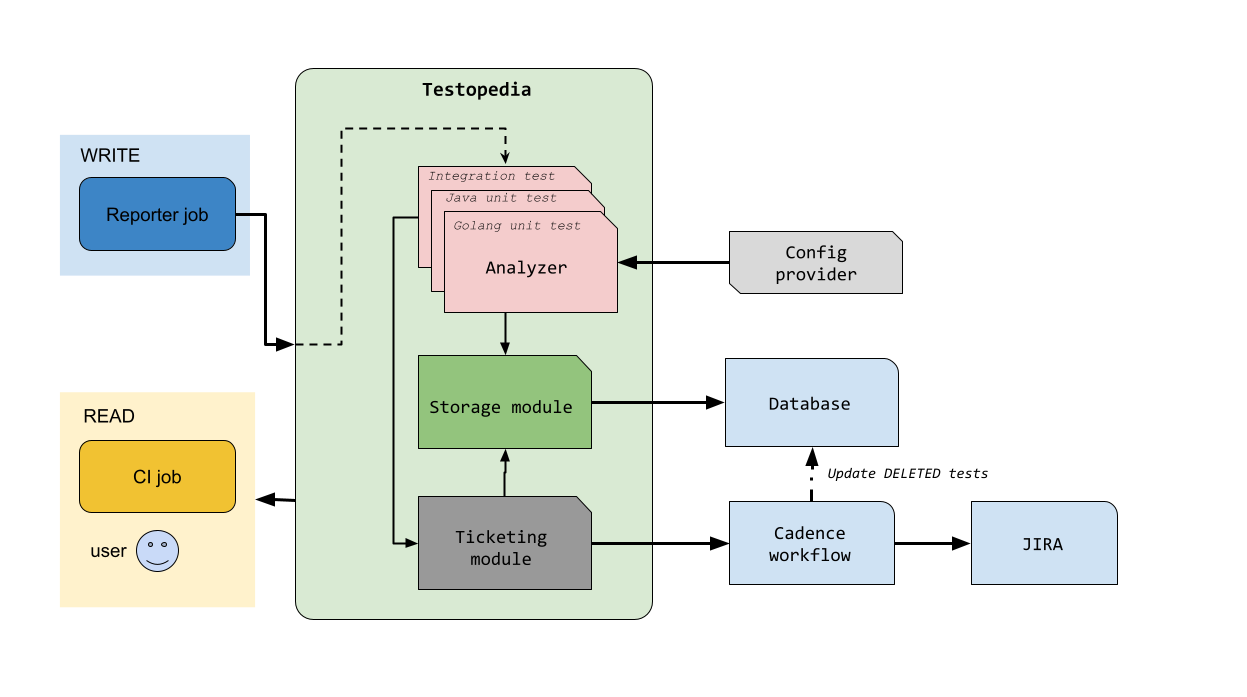
Testopedia keeps track of all the tests Uber runs and categorizes them into different states like new, stable, disabled, unsound, deleted.
The service will automatically move tests between states based on the test statistics it collects (or based on actions like tests being added/deleted from the codebase).
Testopedia uses unique string identifiers (Uber refers to these identifiers as “Fully Qualified Names“) to keep track of the tests. It generates these names based on the domain of the test, its path in the codebase and its target.

When Uber runs tests on a PR, they’ll query Testopedia to figure out which specific tests need to run.
This results in a query like golang.unit/src/infra/*, which returns all the tests within that domain.
One of the challenges Uber faced was figuring out how to make serving these queries efficient. Iterating across the entire database to find all the prefix matches was not acceptable since Uber had millions of tests.
Instead, Uber went with a bucketing algorithm for storing their tests. In some ways, it’s similar to a trie data structure.
Uber maintains a prefix table that stores the tests for each prefix. Here’s an example of how Uber might add a new test golang.unit/a/b/c/d:test to the table.
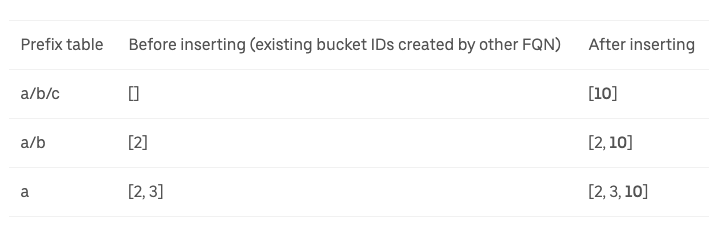
Generate Integer Bucket ID - Each test case is identified by an integer bucket ID, so the first step is to generate that bucket ID. For
golang.unit/a/b/c/d:test, the generated bucket ID is 10.Identify the Prefix - Uber strips away the domain and just looks at the prefix for the test. They look at the first 3 prefixes so in this case it’s
a/b/cAdd to Prefix Layers - First, they add 10 to the
a/prefix. Then, they add 10 to thea/bprefix. Finally, they add 10 to thea/b/cprefix.
When Testopedia gets a query for all the test cases with a certain prefix, they can just look that prefix up in the table and immediately get all the test case bucket IDs for that prefix.
Managing Flaky Tests
When identifying flaky tests, Uber needs to ensure the system isn’t too aggressive at removing unstable tests (while also being useful).
Uber identifies flaky tests with a sliding window algorithm. If a test fails once in the last X window of runs, then it’s classified as unstable. On the other hand, tests are classified as stable if they pass N times consecutively.
The system is also highly extensible. For example, integration tests might be more computationally intensive so they can be likelier to timeout and fail randomly. In this scenario, Testopedia also has percentage-based analyzers that will look at a test’s failure percentage over the last N runs. If the failure rate exceeds the configured threshold then the test will be set as unstable.
Treating Flaky Tests
When a test is marked as flaky, Uber has several strategies to deal with this to ensure that code test coverage is not impacted.
Critical Tests - if a test is marked as critical, then it’ll be run on CI jobs regardless of whether or not it’s set as flaky.
Test Switches - when submitting a PR, engineers can add tags/keywords to enable flaky tests or disable critical tests.
Non-Blocking Mode - Uber’s CI system can also run the flaky tests asynchronously and then send the results to the engineer without blocking the PR.
Testopedia also ensures that the relevant engineering teams are notified when they have flaky tests. Sending a notification for each flaky test would quickly overwhelm the system (and also overwhelm engineers) so Testopedia batches flaky test notifications by domain/prefix/severity.
Then, each engineering team can set their specific notification frequency for how frequently they want to be alerted about flaky tests.

