The Architecture of Dropbox's Load Balancing Service
How Dropbox reduced spend on hardware by improving their load balancing. Plus, how to move off heroku and tips on how much you should charge for consulting.
Hey Everyone!
Today we’ll be talking about
The Architecture of Dropbox’s Load Balancing Service
How Dropbox reduced fleet sizes by 25% by improving their load balancing between services in their backend
The steps involved in the Load Balancing service
The metrics Dropbox uses to evaluate load balancer performance
Tech Snippets
If you need the money, don’t take the job
Please just stop saying “just”
Moving off Heroku, slowly
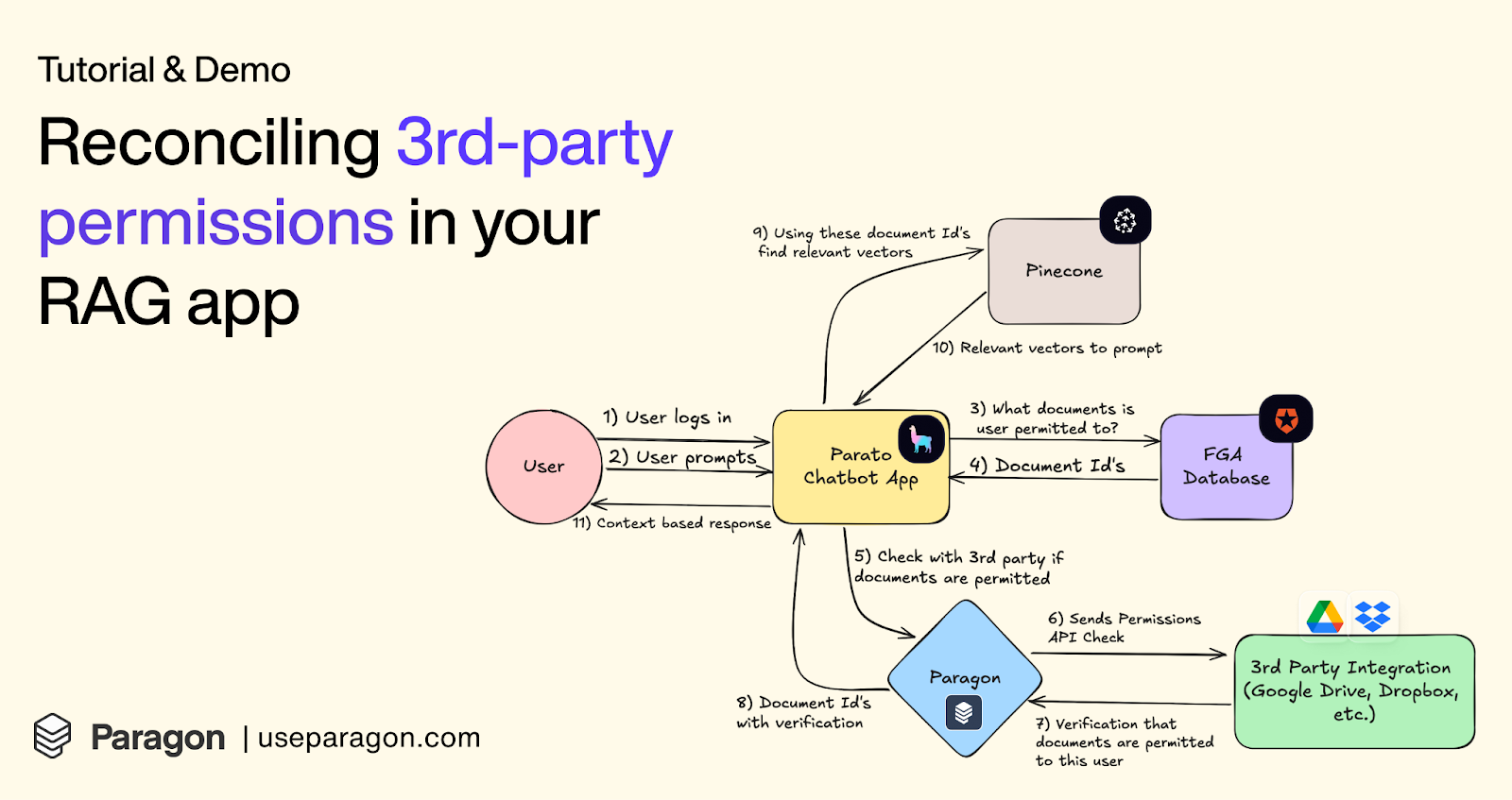
Handling permissions is easy in an auth-based architecture.
But that all goes out the window when you’re ingesting an organization’s data from 3rd party sources (Google Drive, Slack) in a shared vector store.
If you’re building an AI chatbot or enterprise search into your product, you need to ensure only the data and files the querying user has access to are retrieved.
This tutorial and video walkthrough (with sample code) shares how you can implement a permissions system into your RAG app, using the following tools:
Okta FGA as the permissions graph database
Llama-index for the front-end and RAG orchestration
Pinecone as the vector store
Paragon as the 3rd-party data & permissions ingestion infrastructure
sponsored
The Architecture of Dropbox’s Load Balancing Service
Dropbox is one of the largest file storage platforms in the world with over 700 million registered users. They handle a massive amount of data with exabytes (1 billion gigabytes) stored across multiple data centers around the globe.
They host over 90% of user data on their own custom-built infrastructure while also relying on AWS. Back in 2018, they made headlines by moving most of their data off AWS S3 to their own data centers - a decision that saved them $75 million within two years.
Dropbox uses a load balancing service called Robinhood to route traffic between their internal services. Robinhood is responsible for ensuring that requests are distributed evenly across servers so that hardware resources are used efficiently (you don’t have a situation where half the servers running at 95% CPU-utilization and the other half of the servers at 10% CPU-utilization).
Prior to deploying Robinhood in 2020, Dropbox services suffered from significant issues with uneven load distribution among their backend machines. The root cause of this was hardware differences between the servers in their fleet and limitations in their load balancing strategies.
Because of their inefficient utilization of hardware, service teams were over-provisioning their fleets with extra servers and wasting money.
In 2020, Dropbox deployed the Robinhood load balancing service to solve these load balancing challenges. Since then they've been able to reduce fleet sizes by 25% for some of their largest services while improving reliability (by minimizing overloaded instances). This translates to millions of dollars saved every year.
Last week, Dropbox published a fantastic blog post talking about the architecture of Robinhood. We’ll be discussing some of the key details below.
Architecture of Robinhood Load Balancing Service
Here’s the architecture of Robinhood within a single data center.

The steps involved are…
Client requests IP address - When a backend service (
clientin the diagram) at Dropbox needs to make a request to another service (servicefooin the diagram), it first contacts the service discovery system to get the correct IP address.Service Discovery System requests Routing Info - The service discovery system gets updates from the routing database (Routing DB) about the server IP addresses for the different services at Dropbox and how much load each of their servers have. The routing database is a ZooKeeper/etcd-based database.
The service discovery system also queries information from the Load Balancing Service (LBS), a system responsible for collecting load information and generating routing information with weights for each of the service’s endpoints (
foo’s endpoints in this case).Service Foo sends Load Reports to Robinhood Proxy - In order to keep the Load Balancing Service updated, the services at Dropbox will continuously send load reports to the Robinhood Proxy. These reports will contain metrics like CPU utilization, the number of in-flight requests and more.
Robinhood Proxy sends Load Reports to LBS - The Robinhood Proxy aggregates these load reports and forwards them to the Load Balancing Service (LBS). Adding in the Robinhood proxy (instead of having services send load reports to LBS directly) greatly reduces the number of connections that LBS has to manage and minimizes the memory pressure on LBS.
LBS distributes load and writes to Routing DB - The Load Balancing Service will process the reports from the Robinhood proxy and use various load balancing strategies to determine optimal traffic distribution.
Some of the metrics LBS uses include
CPU Utilization - the primary load balancing metric for most services at Dropbox
In-flight Requests - used for services that are not bottlenecked by CPU
Geographic Location - LBS has locality information so it can route requests to the nearest data center to minimize latency
Routing DB sends updates to Service Discovery - As the Load Balancing Service updates the weights for the different service endpoints across Dropbox, this information gets written to the Routing DB. Routing DB notifies the service discovery system in real-time.
How Dropbox Evaluates Load Balancer Performance
When you’re evaluating load balancer performance, the key metric to measure is server utilization. You want the load to be spread evenly across the instances in your cluster.
Dropbox uses several ratios to measure the effectiveness of their load balancing system:
max/avg ratio: The maximum CPU utilization across all instances of a service divided by the average CPU utilization of all instances of that service.
p95/avg ratio: The 95th percentile CPU utilization across all instances of a service divided by the average CPU utilization of all instances of that service.
p5/avg ratio: The 5th percentile CPU utilization across all instances divided by the average CPU utilization of all instances of that service. (This helps identify servers that are significantly underutilized)
Lessons Learned
Through building and deploying Robinhood, the Dropbox team learned several valuable lessons:
Keep Configuration Simple - While Robinhood offers many configuration options, they found that having good defaults was crucial. Most services just need basic configuration, and simpler configs save engineering time and reduce errors.
Minimize Client Changes - Client-side changes can take months to roll out across all services since some services deploy infrequently. The team learned to put as much complexity as possible in the LBS rather than requiring client changes. They stuck with weighted round-robin on the client side and haven't changed it since deployment.
Plan Migration Early - The team discovered that migration strategy needs to be considered during initial design. Migration takes significant engineering time and carries reliability risks. The more you require from service owners during migration, the more difficult it becomes. The Robinhood team had to spend extra time redesigning their migration process because it wasn't well planned initially.
This is a condensed summary, so you can get all the details by reading the full article here.
Handling permissions is easy in an auth-based architecture.
But that all goes out the window when you’re ingesting an organization’s data from 3rd party sources (Google Drive, Slack) in a shared vector store.
If you’re building an AI chatbot or enterprise search into your product, you need to ensure only the data and files the querying user has access to are retrieved.
This tutorial and video walkthrough (with sample code) shares how you can implement a permissions system into your RAG app, using the following tools:
Okta FGA as the permissions graph database
Llama-index for the front-end and RAG orchestration
Pinecone as the vector store
Paragon as the 3rd-party data & permissions ingestion infrastructure
sponsored