The Architecture of Canva's Data Platform
We'll talk about Snowflake and how Canva built a monitoring system around it. Plus, how to optimize code, why Unicode is harder than you think, automating your job search and more.
Hey Everyone!
Today we’ll be talking about
The Architecture of Canva’s Data Platform
Introduction to Snowflake
Architecture of Canva’s Data Platform
How Canva Monitors their Snowflake Usage to avoid Expensive Surprises
Tech Snippets
The Four Kinds of Optimization
Unicode is Harder Than You Think
How I Automated My Job Application Process
Three Bucket Framework for Engineering Metrics
The Architecture of Canva's Data Platform
Canva is an online graphic design platform that lets you create social media posts, posters, videos, logos and more. They have a ton of pre-built templates that help you create professional looking designs even if you have the visual-design skills of a 4 year old.
The company was founded in 2013 and has exploded in popularity with hundreds of millions of users globally. This hyper growth has caused a ton of interesting engineering challenges, particularly with their data platform.
Canva uses Snowflake for the core of their data platform. They store over 25 petabytes of data and execute over 90 million queries a month. Over two-thirds of employees at Canva use Snowflake in some way (writing SQL queries, relying on business-intelligence dashboards, etc.)
However, Snowflake costs can get out-of-hand very quickly if you don’t effectively monitor and optimize your usage. Canva wrote a fantastic engineering blog on the tooling they built to do this.
Introduction to Snowflake
Snowflake is a cloud data warehouse platform that has grown incredibly quickly since its launch in 2014.
At the time of their founding, companies were mainly using on-prem data warehouses like Teradata or Oracle. However, these were super expensive to scale and maintain. You’d have to purchase a ton of hardware upfront and managing all the infrastructure was a huge pain.
In response, Snowflake built a cloud-native data warehouse that runs on top of AWS, Azure and Google Cloud. You pick the cloud provider that fits with the rest of your infrastructure.
Data in Snowflake is stored in a columnar format in “micro-partitions”. These are contiguous storage units that contain 50-500 mb of data and help massively with speeding up analytical queries.
You can access data in Snowflake with SQL, the API (with connectors for Python, Java, NodeJS, etc.), the web interface and other third party tools.
Some of the core selling points of Snowflake are
Separation of Storage and Compute - Snowflake allows you to scale your compute resources independently of your storage resources. If you have a small dataset but need extensive processing, then you can scale up your compute resources without having to pay for storage you don’t need. AWS Redshift added this capability with RA3 instances in late 2019.
Low Management and Security - Snowflake is cloud-native so it has far lower maintenance than an on-prem data warehouse. It also provides a ton of security features like Time Travel that lets you access historical data versions for data recovery and auditing.
Data Integrations - Snowflake supports both structured and semi-structured data formats like CSV, JSON, Avro, Parquet and more. It also has integrations to a ton of data tools like Kafka, Spark, Tableau, etc.
The main cons of Snowflake are vendor lock-in and (potentially) the costs.
Snowflake’s pricing can be notoriously complex and difficult to predict. Not monitoring/optimizing your usage can quickly result in a very expensive surprise.
Snowflake at Canva
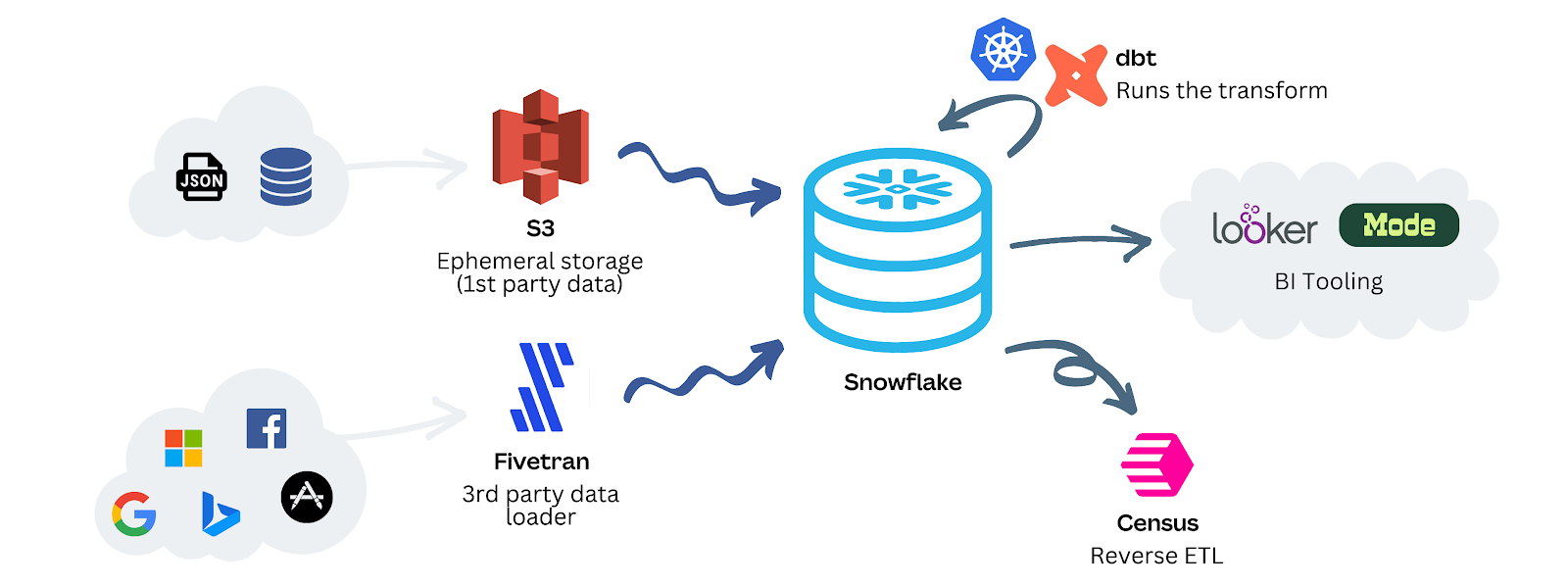
Here are the steps in Canva’s Data Platform
Data Ingestion - First party data (generated by services at Canva) is ingested through AWS S3. Third party data (Facebook ad spend results, Google organic search data, etc.) is ingested with Fivetran for ETL
Data Transformation - Canva uses dbt for transforming and cleaning raw data into a format that supports analysis and reporting. dbt is an open source tool where you can write your data transformation logic in SQL or Python and organize it into maintainable components.
Data Views - Canva uses Census to synchronize enriched datasets to third-party systems. They also use Looker and Mode for data visualization and exploration.
Canva’s Snowflake Monitoring System
In order to avoid overspending, the Canva team built out an extensive monitoring system around Snowflake and their usage.
They started by using Snowflake’s account_usage.query_history view to collect usage data and they stored this in a dedicated dbt project. They also captured detailed metadata on all their other dbt runs (for their main data transformations) and stored this data in S3.
In order to link specific Snowflake queries with the corresponding dbt models, Canva developed a custom dbt query tagging macro that appended JSON metadata to each query. They could use this to track the usage at a per-query level and then assign costs to individual queries and transformations.
With this foundation, Canva created dashboards that provided Data Platform engineers with real-time metrics on how Snowflake was being used, which teams were incurring costs and how usage could be optimized.
