How PayPal uses Graph Databases
Plus, things you should know about Time Zones, advice from the co-founder of HashiCorp on building large technical projects and more!
Hey Everyone!
Today we’ll be talking about
How PayPal uses Graph Databases for Fraud Detection
Introduction to Graphs
Brief Intro to Graph Databases and their Benefits
How PayPal uses Graph Databases for Fraud Detection
The Architecture of PayPal’s Graph Database
Tech Snippets
How Netflix detects Speech and Music in their Content
How to Build Large Technical Projects
Moving From IC to Engineering Manager
Falsehoods programmers believe about time zones
How PayPal uses Graph Databases
One of the most challenging parts of running a fintech company is dealing with online fraud.
In fact, when PayPal first started in the early 2000s, the company came extremely close to dying due to the fraud losses. They were losing millions of dollars a month because of Russian mobsters (in 2000, the company lost more from fraud than they made in revenue that year) and were also seeing those losses increase exponentially.
Fortunately, their engineers were able to build an amazing fraud-detection system that ended up saving the company. In fact, PayPal was actually the first company to use CAPTCHAs for bot-detection at scale.
Nowadays, they rely heavily on real-time Graph databases for identifying abnormal activity and shutting down bad actors.
Xinyu Zhang wrote a fantastic blog post on how PayPal does this.
We’ll start by giving an introduction to graphs and graph database. Then, we’ll delve into the architecture of PayPal’s graph database and how they’re using the platform to prevent fraud.
If you want fully editable, spaced-repetition flash cards on all the core concepts we discuss in Quastor, check out Quastor Pro. It’s super useful for becoming a better backend developer and also for system design-style interviews.
Introduction to Graphs
Graphs are a very popular way of representing relationships and connections within your data.
They’re composed of
Vertices - These represent entities in your data. In PayPal’s case, vertices/nodes represent individual users or businesses.
Edges - These represent connections between nodes. A connection could represent one user sending money to another user. Or, it could represent two users sharing the same attributes (same home address, same credit card number, etc.)
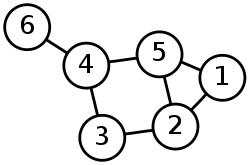
Graphs can also get a lot more complicated with edge weights, edge directions, cyclic/acyclic and more.
Graph Databases
Graph databases exist for storing data that fits into this paradigm (vertices and edges).
You may have heard of databases like Neo4j, AWS Neptune or ArangoDB. These are NoSQL databases specifically built to handle graph data.
There’s quite a few reasons why you’d want a specialized graph database instead of using MySQL or Postgres (although, Postgres has extensions that give it the functionality of a graph database).
Faster Processing of Relationships - Let’s say you use a relational database to store your graph data. It will use joins to traverse relationships between nodes, which will quickly become an issue (especially when you have hundreds/thousands of nodes)
On the other hand, graph databases use pointers to traverse the underlying graph. Each node has direct references to its neighbors (called index-free adjacency) so traversing from a node to its neighbor will always be a constant time operation in a graph database.
Here’s a really good article that explains exactly why graph databases are so efficient with these traversals.Graph Query Language - Writing SQL queries to find and traverse edges in your graph can be a big pain. Instead, graph databases employ query languages like Cypher and Gremlin to make queries much cleaner and easier to read.
Here’s an example SQL query and an equivalent Cypher query to find all the directors of Keanu Reeves movies.
### SQL
SELECT director.name, count(*)
FROM person keanu
JOIN acted_in ON keanu.id = acted_in.person_id
JOIN directed ON acted_in.movie_id = directed.movie_id
JOIN person AS director ON directed.person_id = director.id
WHERE keanu.name = 'Keanu Reeves'
GROUP BY director.name
ORDER BY count(*) DESC
### Cypher
MATCH (keanu:Person {name: 'Keanu Reeves'})-[:ACTED_IN]
->(movie:Movie),
(director:Person)-[:DIRECTED]->(movie)
RETURN director.name, count(*)
ORDER BY count(*) DESCAlgorithms and Analytics - Graph databases will come integrated with commonly used algorithms like Djikstra, BFS/DFS, cluster detection, etc. You can easily and quickly runs tasks for things like
Path Finding - find the shortest path between two nodes
Centrality - measure the importance or influence of a node within the graph
Similarity - calculate the similarity between two nodes
Community Detection - evaluate clusters within a graph where nodes are densely connected with each other
Node Embeddings - compute vector representations of the nodes within the graph
Graph Databases at PayPal
PayPal uses graph databases to eliminate fraud by analyzing their user data from three perspectives:
Asset Sharing - When two accounts share the same attributes (home address, credit card number, social security number, etc.) then PayPal can place an edge linking them in the database. Using this, they can quickly identify abnormal behaviors. If 50 accounts all share the same 2 bedroom apartment as their home address, then that’s probably worth investigating.
Transaction Patterns - When two users transact with each other, that is stored as an edge in the graph database. PayPal is able to quickly analyze all their transactions and search for strange behaviors. A common pattern that’s typically flagged for fraud is the “ABABA“ pattern where users A and B will repeatedly send money back and forth between each other in a very short period.
Graph Features - The structural characteristics of the graph (connected communities of accounts, vertices that have lots of connections, degree of clustering amongst nodes, etc.) are very useful for predicting potential fraud. For example, if you have a dense cluster of 10 accounts (these 10 accounts have a lot of edges connecting them all) where 5 are identified as fraudsters, you might want to pay extra attention to the remaining 5 accounts.
This is just a short list of some of the techniques PayPal uses. They definitely run a lot more different types of graph analysis algorithms that they didn’t reveal in the blog post.
It probably wouldn’t be great if you had to tell the CTO you accidentally cost them $30 million in fraud losses because you revealed all their fraud detection techniques on the company engineering blog.
PayPal’s Graph Database Architecture

PayPal uses Aerospike and Gremlin for their graph database. Aerospike is an open-source, distributed NoSQL database that offers Key-Value, JSON Document and Graph data models. Gremlin is a graph traversal language that can be used for defining traversals. It’s part of Apache TinkerPop, an open source graph computing framework.
The database has separate read and write paths.
Write Path
For the write path, the graph database ingests both batch and real-time data.
In terms of batch updates, there’s an offline channel set up for loading snapshots of the data. It supports daily or weekly updates.
For real-time data, this comes from a variety of services at PayPal. These services all send their updates to Kafka, where they’re consumed by the Graph data Process Service and added to the database.
Read Path
The Graph Query Service is responsible for handling reads from the underlying Aerospike data store. It provides template APIs that the upstream services (for running the ML models) can use.
Those APIs wrap Gremlin queries that run on a Gremlin Layer. The Gremlin layer converts the queries into optimized Aerospike queries, where they can be run against the underlying storage.
For more details, check out the article here.