How Lyft Processes Terabytes of Real Time Data
Lyft switched their data store from Apache Druid to ClickHouse. We'll give brief overviews of Druid and ClickHouse and also talk about why they shifted.
Hey Everyone!
Today we’ll be talking about
Why Lyft Moved from Druid to ClickHouse
A brief overview of Apache Druid
Issues Lyft faced with Druid
Overview of ClickHouse and the benefits Lyft saw
Challenges Lyft has faced since Migrating
Tech Snippets
Demystifying the Math behind Transformers
Benchmarking Programming Languages with N Queens and Sudoku
Variability, Not Repetition, is the Key to Mastery
Why Lyft Moved to ClickHouse
Lyft is one of the largest ride-sharing companies in the world with over 20 million active riders and hundreds of millions of completed rides every quarter.
In order to operate, Lyft needs to handle lots of data in real-time (sub-second ingestion/queries). They have to do things like
Real Time Geospatial Querying - when a user opens the app, Lyft needs to figure out how many drivers are available in that specific area where the user is. This should be queried in under a second and displayed on the app instantly.
Manage Time Series Data - When a user is on a ride, Lyft should be tracking the location of the car and saving this data. This is important for figuring out pricing, user/driver safety, compliance, etc.
Forecasting and Experimentation - Lyft has features like surge pricing, where the price of Lyft cars in a certain area might go up if there’s very few drivers there (to incentivize more drivers to come to that area). They need to calculate this in real time.
To build these (and many more) real-time features, Lyft used Apache Druid, an open-source, distributed database.
In November of last year, they published a fantastic blog post delving into why they’re switching to ClickHouse (another distributed DBMS for real time data) for their sub-second analytics system.
In this article, we’ll give an overview of ClickHouse, Druid and talk about the reasons that led Lyft to switch over.
Apache Druid Overview
Druid was created in the early 2010s in the craze around targeted advertising. The goal was to create a system capable of handling the massive amount of data generated by programmatic ads.
The creators wanted to quickly ingest terabytes of data and provide real-time querying and aggregation capabilities. Druid is open source and became a Top-Level project at the Apache Foundation in 2019.
Druid is meant to run as a distributed cluster (to provide easy scalability) and is column-oriented.
In a columnar storage format, each column of data is stored together, allowing for much better compression and much faster computational queries (where you’re summing up the values in a column for example).
When you’re reading/writing data to disk, data is read/written in a discrete unit called a page. In a row-oriented format, you pack all the values from the same row into a single page. In a column-oriented format, you’re packing all the values from the same column into a single page (or multiple adjacent pages if they don’t fit).
For more details, we did a deep dive on Row vs. Column-oriented databases that you can read here.
Druid is a distributed database, so a Druid cluster consists of
Data Servers - stores and serves the data. Also handles the ingestion of streaming and batch data from the master nodes.
Master Servers - handles ingesting data and assigning it to data nodes.
Query Servers - Processes user queries and routes them to the correct data nodes to be served.
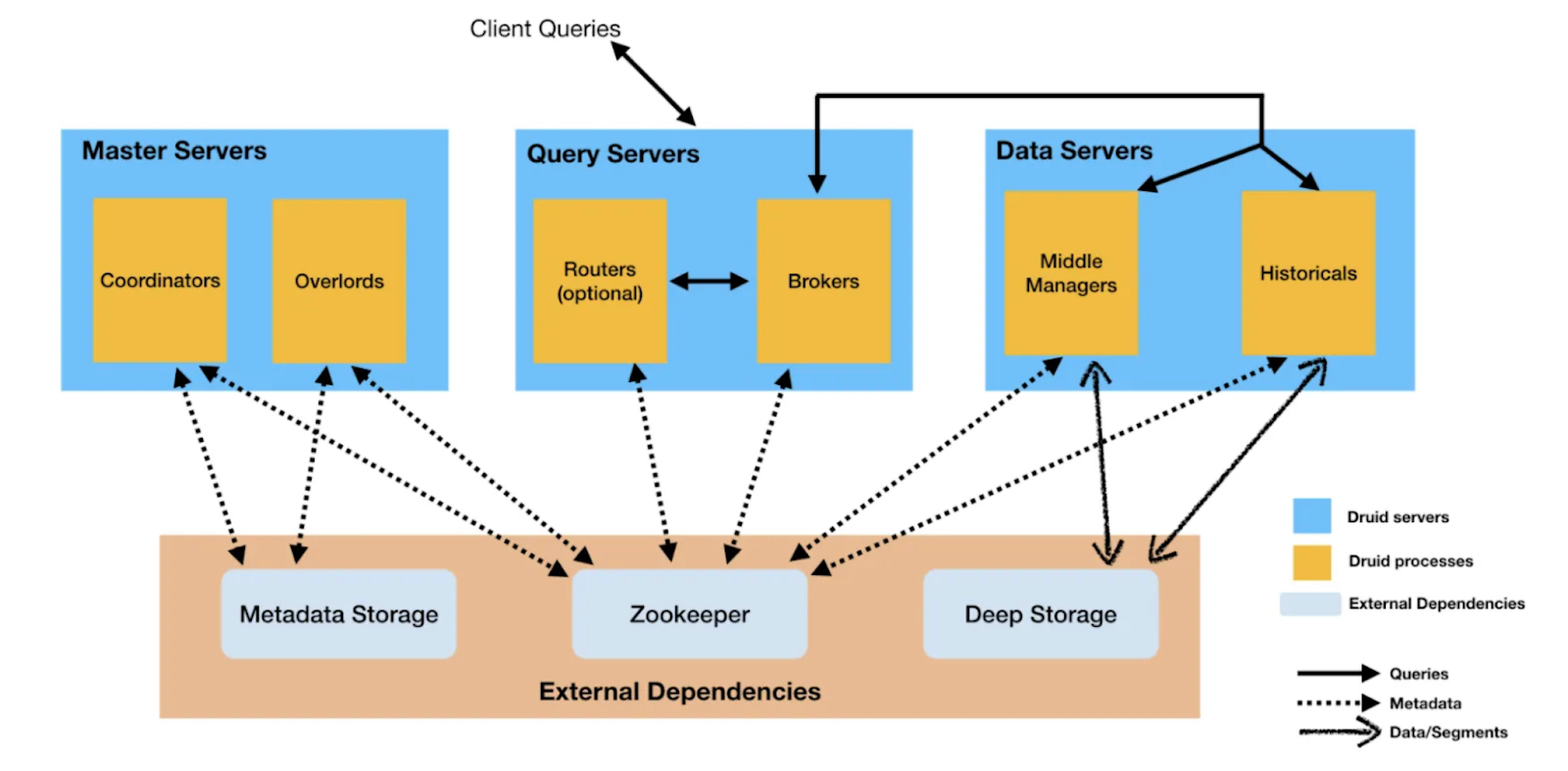
For a more detailed overview, check the docs here.
Issues with Druid
At Lyft, the main issue they faced with Druid was the steep ramp-up for using/maintaining the database. Writing specifications for how the database should ingest data was complex and it also required a deep understanding of the different tuning mechanisms of Druid. This led to a lack of adoption amongst engineers at the company.
Additionally, Lyft has been running a lot leaner over the last year with a focus on cost-cutting initiatives. This meant that they were hyper-focused on different priorities and couldn’t spend as much time upgrading and maintaining Druid.
As a result, Druid was under-invested due to a lack of ROI (engineers weren’t using it… so they weren’t getting a return from investing in it).
Lyft engineers had to make a choice…
Should they invest more into Druid and try to increase adoption, or did it make more sense to switch to another solution.
ClickHouse Overview
ClickHouse is a distributed, open source database that was developed 10 years ago at Yandex (the Google of Russia).
It’s column-oriented with a significant emphasis on fast read operations. The database uses clever compression techniques to minimize storage space while enhancing I/O efficiency. It also uses vectorized execution (where data is processed in batches) to speed up queries.
You can read more details on the architectural choices of ClickHouse here.
ClickHouse gained momentum at Lyft as teams began to adopt the database. This led to the Lyft team’s option of replacing Druid with ClickHouse for their real-time analytics system.
They saw 5 main benefits of ClickHouse over Druid
Simplified Infrastructure Management - Druid has a modular design (with all the different server types and each server type having different roles) which made it more complex to maintain. ClickHouse’s design and architecture was found to be easier to manage.
Reduced Learning Curve - Lyft engineers are well versed in Python and SQL compared to Java (Druid is written in Java) so they found the ClickHouse tooling to be more familiar. Onboarding was easier for devs with ClickHouse.
Data Deduplication - ClickHouse natively supported data deduplication. It wasn’t handled as effectively by Druid.
Cost - Lyft found running ClickHouse to be 1/8th the cost of running Druid
Specialized Engines - ClickHouse provides specialized functionalities that make it easier to do tasks like replicate data across nodes, deduplicating data, ingesting from Kafka, etc.
To help with the decision, they created a benchmarking test suite where they tested the query performance between ClickHouse and Druid.
They saw improved performance with ClickHouse despite seeing a few instances of unreliable (spiky and higher) latency. In those cases, they were able to optimize to solve the issues.
You can read more about the specific optimizations Lyft made with ClickHouse in the blog post here.
Challenges Faced
The migration to ClickHouse went smoothly. Now, they ingest tens of millions of rows and execute millions of read queries in ClickHouse daily with volume continuing to increase.
On a monthly basis, they’re reading and writing more than 25 terabytes of data.
Obviously, everything can’t be perfect however. Here’s a quick overview of some of the issues the Lyft team is currently resolving when using ClickHouse
Query Caching Performance - engineers sometimes see variable latencies, making it harder to promise SLAs for certain workloads. They’ve been able to mitigate this with caching queries using an appropriate cache size and expiration policy.
Kafka Issues - ClickHouse provides functionalities to ingest data from Kafka but the Lyft team faced difficulties with using this due to incompatible authentication mechanisms with Amazon Managed Kafka (AWS MSK).
Ingestion Pipeline Resiliency - Lyft uses a push-based model to ingest data from Apache Flink to ClickHouse. However, they’re using ZooKeeper for configuration management so ingestion can occasionally fail when ZK is in resolution mode (managing conflicting configurations/updates). However, the engineers are planning on retiring ZooKeeper.
For more details, you can read the full article here.