Load Balancing Algorithms Explained Visually
We delve into Round Robin, Weighted Round Robin, Least Connections, Power of Two Choices and much more.
Hey Everyone!
Today we’ll be talking about
Load Balancing Algorithms Explained Visually - We’ll be delving into load balancing strategies. We’ll talk about
Factors to Consider
Round Robin and Weighted Round Robin
Least Connections and Least Response Time
Power of Two Random Choices and ALG
Consistent Hashing and Maglev Hashing
Tech Snippets
How Amazon does CI/CD
How Shopify uses the 25% Rule for Tech Debt
Python 3.13 gets a JIT Compiler
How to get things done as a software engineer
Prioritizing with the Code Quality Pyramid
Load Balancing Algorithms Explained Visually
As your website scales, you’ll eventually reach a point where you need to add more servers. The number of incoming requests will be too great for a single computer to handle, so you’ll need to split up the workload between multiple machines.
When you do this, a crucial decision is how to assign requests to machines.
Do you use a round-robin approach where you rotate between all the machines one-by-one? Or maybe poll all the servers and ask which has the least workload and send the request there? What about using a random number generator to assign requests to different machines? (this is probably not a good idea)
You’ll need some load balancing algorithm to decide how to route jobs to machines. There’s a ton of different options available with different tradeoffs.
In this article, we’ll delve into the trade-offs, talk about some different load balancing algorithms, give real world case studies and delve into pros and cons.
Factors of a good load balancing algorithm
So, what are the factors that you need to consider when picking a load balancing strategy for your workload?
Key areas to consider are
Resource Utilization - how efficiently are the servers in your cluster being used? If half your servers are at 100% utilization and the others are at 10%, then that’s obviously not efficient. You want the request load to be split evenly across all your machines so you’re handling user traffic without lighting money on fire with completely-idle servers.
Real-time Adaptability - If there’s a change in user traffic or server health, can the load balancing algorithm adapt? You can split up load balancing algorithms into static and dynamic algorithms. Static algorithms will distribute traffic to your machines based on predetermined rules whereas dynamic algorithms will factor in the health of your servers when making a decision (they measure health with metrics like CPU/RAM utilization, concurrent users, etc.).
Session Persistence - When a user makes multiple requests, do those requests need to all go to the same server? Perhaps each one of your servers has its own in-memory cache. That cache would be quite inefficient if consecutive requests from the same user weren’t being directed to the same server. On the other hand, if your servers are completely stateless (they’re relying on some external cache and database) then you might not care about session persistence.
Compute - How much processing power is the load balancing algorithm taking? If you’re at Google scale, you have to handle millions of requests per second. Hopefully you realize that extremely computationally expensive == not good.
Complexity - Remember that someone needs to configure, maintain and debug the load balancers. It’s important to keep it simple (stupid).
Different load balancing algorithms make trade-offs between these factors. Some load balancers are static (don’t take into account server conditions) but they’re extremely efficient and can handle a very high throughput. Others might be dynamic and offer better resource-utilization at the cost of handling fewer requests per second.
We’ll go through some popular load balancing strategies (and their variants)
Round Robin and Weighted Round Robin
Least Connections and Least Response Time
Power of 2 Random Choices and AGL
Consistent Hashing and Maglev Hashing
Round Robin
You might remember Round Robin scheduling from your operating systems class. It’s one of the simplest load balancing strategies where you go through each server one by one and assign requests to each.
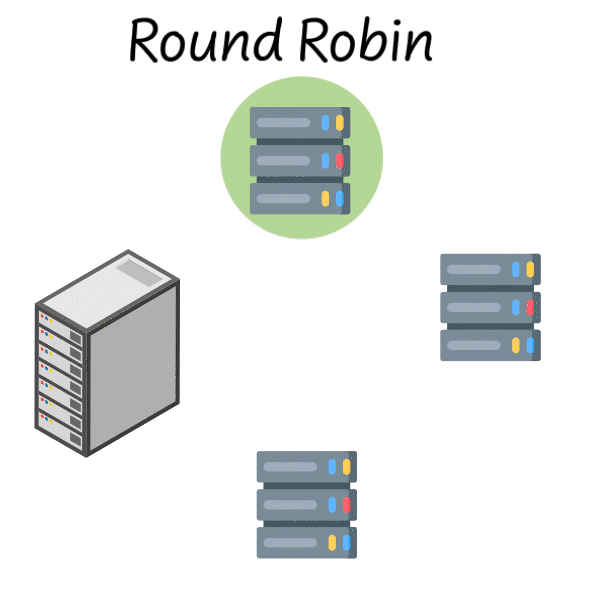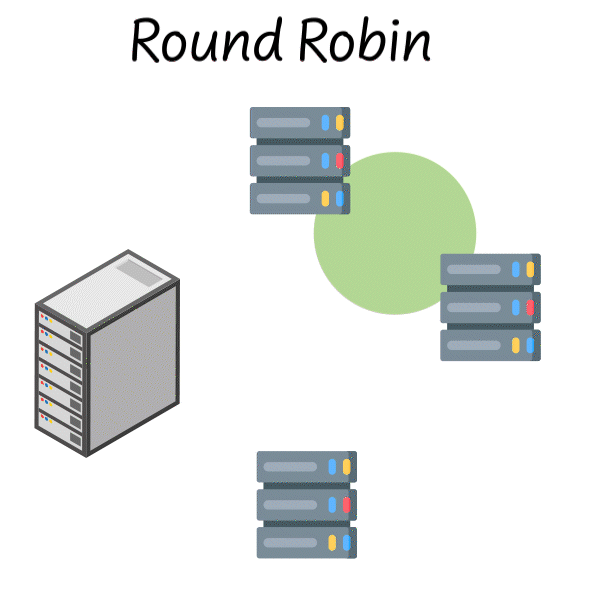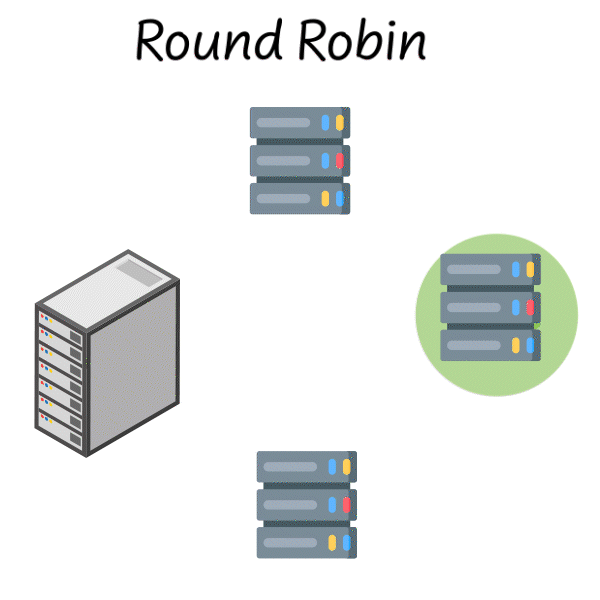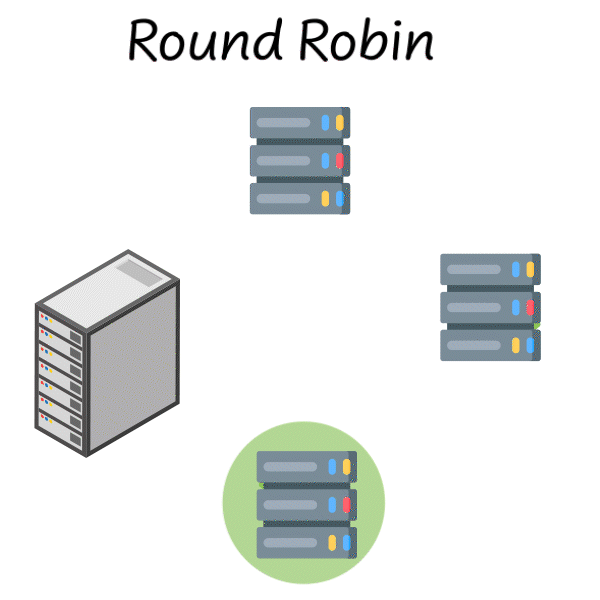
Assign a request to server 1, then server 2, then server 3, then back to server 1 and so on…
Pros
The main pro of Round Robin is that it’s extremely simple to conceptualize and implement. It’s one of the most “intuitive” solutions and it’s very commonly used. All load balancing solutions will offer Round Robin as a built-in choice.
It works very well when
Each request takes a similar amount of compute
All the machines in your server pool have similar capacity
Cons
A potential issue with Round Robin is that it’s static. It doesn’t consider the current conditions/capacity of your servers. You might have some machines that are more powerful. Or perhaps some of the servers in your fleet are only operating at 50% capacity due to some issue.
Naive Round Robin is completely oblivious to this and it can result in bad scheduling decisions. This brings us to Weighted Round Robin.
Weighted Round Robin (WRR)
In Weighted Round Robin, you assign a weight to each of the machines in your server pool (based on CPU, RAM, etc.). Servers with higher capacity get a higher weight.
Then, you distribute requests in proportion with these weights. If server A has a weight of 6 and server B has a weight of 4, then out of every 100 requests, server A will get 60 and server B will get 40.
Note that these weights are often predefined, so Weighted Round Robin is often considered a static load balancing algorithm. WRR is not polling your servers or doing health checks so it’s unable to respond in real-time to any issues you might be facing.
Additionally, both Round Robin and Weighted Round Robin do not consider the processing necessary to complete the request.
For example, you might have a website where some of the requests require intense CPU-processing plus some expensive database lookups. Other user requests might be answered by a quick cache lookup. Round Robin and Weighted Round Robin do not differentiate between these requests. They just assume every request is the same unless otherwise configured.
To solve this issue, we’ll look at dynamic load balancing algorithms.
Least Connections and Least Response Time
If you’re looking for a dynamic load balancing algorithm, then Least Connections and Least Response Time are popular choices.
With this strategy, you poll the servers and ask about their current load. This could be the number of users they are currently serving (least connections) or you could just look at which server responds the fastest (least response time).
Then, you send the request to the server that’s currently handling the least load.
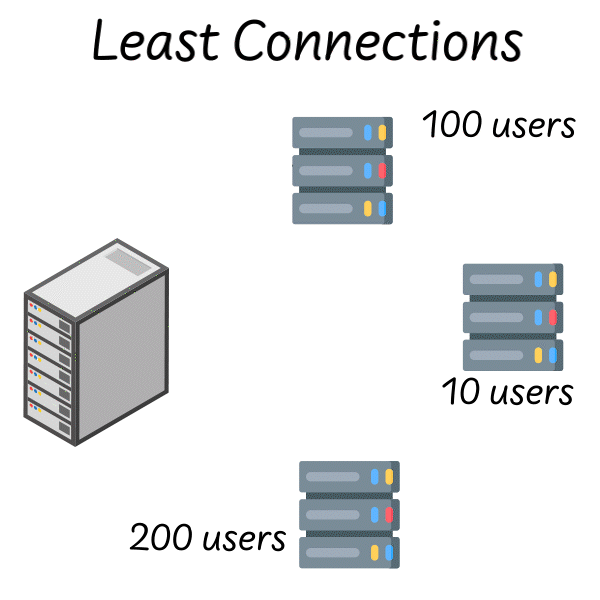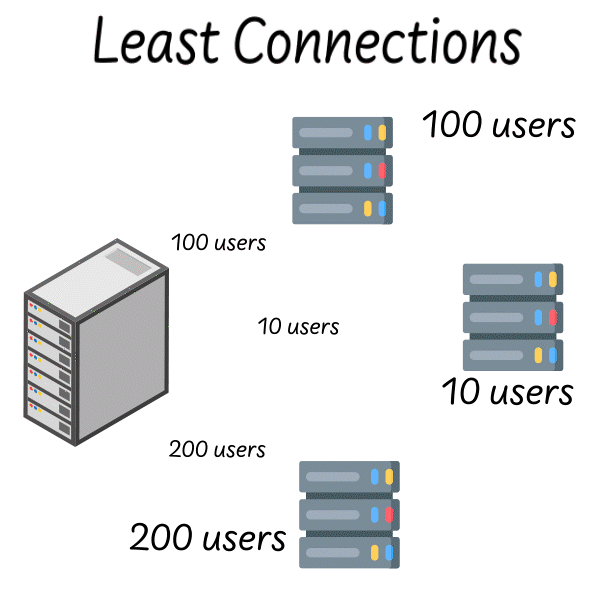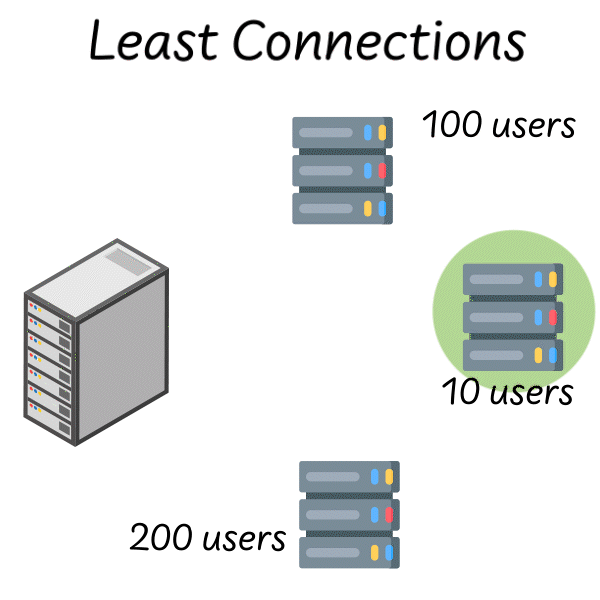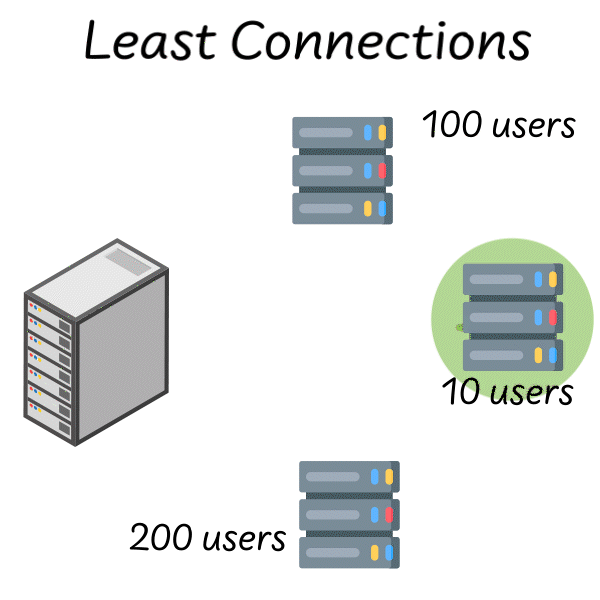
The load balancer polls servers 1, 2 and 3. They each respond with the number of concurrent users they’re currently managing. The load balancer sends the request to server 2 since it only has 10 users.
Pros
As mentioned, the main pro of Least Connections / Least Response time is that it’s dynamic, so it considers the current load of each of the servers when making a decision. If a server is under very heavy load, that machine will stop getting additional user requests (assuming the other servers in the cluster have less load).
This makes these load balancing strategies ideal for when you have variable-length user requests. Perhaps some of the user requests require intensive CPU-processing plus some expensive database lookups. Other user requests might just require a quick cache lookup.
As we mentioned earlier, using a naive round robin strategy wouldn’t differentiate between those two.
On the other hand, Least Connections/Least Response Time looks at the actual load the servers are under and uses that to make decisions. This allows them to perform much more efficiently when requests are highly variable.
Cons
The trade-off with Least Connections is that it’s much more difficult to implement compared to Round Robin. You have to implement polling to constantly get updates on how much load each server is under.
Figuring out the right frequency for how often you should poll is not easy. If you don’t poll frequently, then the algorithm becomes less effective since it doesn’t have up-to-date data on what servers are under what strain. On the other hand, polling too much will put excessive load on your load balancer, network and servers.
The Power of Two Random Choices is another load balancing algorithm that is dynamic (it’s based on the current conditions servers are experiencing) but it doesn’t involve polling every single server in your cluster. We’ll delve into that next.
This is an excerpt from our Load Balancing Algorithms Explained Article for Quastor Pro readers. The full article is coming out tomorrow and will also talk about The Power of 2 Random Choices, Consistent Hashing, Maglev Hashing and more.
For detailed tech dives on a huge host of topics in backend and data engineering, check out Quastor Pro.
Readers can typically expense Quastor Pro with their job’s Learning & Development budget. Here’s an email you can send to your manager.



