How Instacart switched from Postgres to DynamoDB
Plus Design Docs at Google, How to Reduce Infrastructure Costs, Netflix's Platform for Serverless Functions and more.
Hey Everyone!
Today we’ll be talking about
Instacart’s Switch from Postgres to DynamoDB
Instacart needed a highly scalable, elastic solution for storing the state of their push notifications
They decided to switch to DynamoDB after comparing the costs versus sharded Postgres
They reduced DynamoDB costs by making some significant changes to their data model
How to use 1:1 Meetings with your Manager to Propel your Career
This is a great video by Rahul Pandey, a former Tech Lead at Facebook and founder of Taro.
Don’t waste your 1:1 meetings on things that can be discussed in the open. Have “awkward” conversations.
Take notes during the meetings in a document that’s shared with your manager. This gives your manager a way to track your progression over time.
Tech Snippets
Design Docs at Google
How to Reduce Infrastructure Costs
How DoorDash Improved Site Performance
A Curated List of Resources on Fuzz Testing
Netflix’s Platform for Serverless Functions
Instacart’s switch to DynamoDB
Instacart is the largest online grocery delivery company in North America, with millions of active users and over 75,000 stores on the platform.
Instacart leans heavily on push notifications to communicate with users. Gig workers need to be notified if there’s a new customer order available for them to fulfill. Customers need to be notified if one of the items they selected is not in stock so they can select a replacement.
For storing the state machine around the messages being sent, Instacart previously relied on Postgres but started to exceed its limits. They explored several solutions and found DynamoDB to be a suitable replacement.
Andrew Tanner is a software engineer at Instacart and he wrote an awesome blog post on why they switched from Postgres to DynamoDB for storing push notifications.
Here’s a summary
The number of push notifications Instacart needed to send was scaling rapidly and would soon exceed the capacities of a single Postgres instance.
One solution would be to shard the Postgres monolith into a cluster of several machines. The issue with this is that the amount of data Instacart stores changes rapidly on an hour-to-hour basis. They send far more messages during the daytime and very few during the night, so using a sharded Postgres cluster would mean paying for a lot of unneeded capacity during off-peak hours.
Instead, they were interested in a solution that supported significant scale but also had the ability to change capacity elastically. DynamoDB seemed like a good fit.
DynamoDB
DynamoDB is a fully managed NoSQL database by AWS; it’s a key-value database with document support. They give you an API that you can use to insert items, create tables, do table scans, etc.
It’s known for its ability to store extremely large amounts of data while keeping read/write latencies stable. Tables are automatically partitioned across multiple machines based on the partition key you select; AWS can autoscale shards based on the read/write volume.
Note - Although DynamoDB’s latencies are stable, it’s slow if you’re dealing with a small workload that can easily fit on a single machine. With DynamoDB, every request has to go through multiple systems (authentication, routing it to the correct partition, etc.) which adds significant latency compared to just using a single postgres machine.

If you’d like to learn more about how to use DynamoDB, Rick Houlihan’s talks are an excellent resource.
Switching to DynamoDB
Based on the SLA guarantees that DynamoDB provides, Instacart was confident that the service could fulfill their latency and scaling requirements.
The main question was around cost. How much cheaper would it be compared to the sharded Postgres solution?
Estimating the cost for Postgres was relatively simple. They estimated the size per sharded node, counted the nodes and multiplied it by the cost per node per month. For DynamoDB, it was more complicated.
DynamoDB Pricing
DynamoDB cost is based on
Amount of data stored in the DynamoDB table
Number of read/write capacity units
Storage is 25 cents for every gigabyte stored per month.
In terms of read/write load, that’s measured using Read Capacity Units (RCUs) and Write Capacity Units (WCUs).
For reads, the pricing differs based on the consistency requirements. Strongly consistent reads up to 4 KB (most up-to-date data) cost 1 RCU while eventually consistent reads (could contain stale data) cost ½ RCU. A transactional read (multiple reads grouped together in a DynamoDB Transaction) will cost 2 RCUs.
The main cost for Instacart, however, would come from WCUs (they’re significantly more expensive than RCUs). The exact price difference depends on your region, pricing model and capacity, but WRUs are 5 times more expensive than RCUs for US East.
How Instacart Minimized Costs
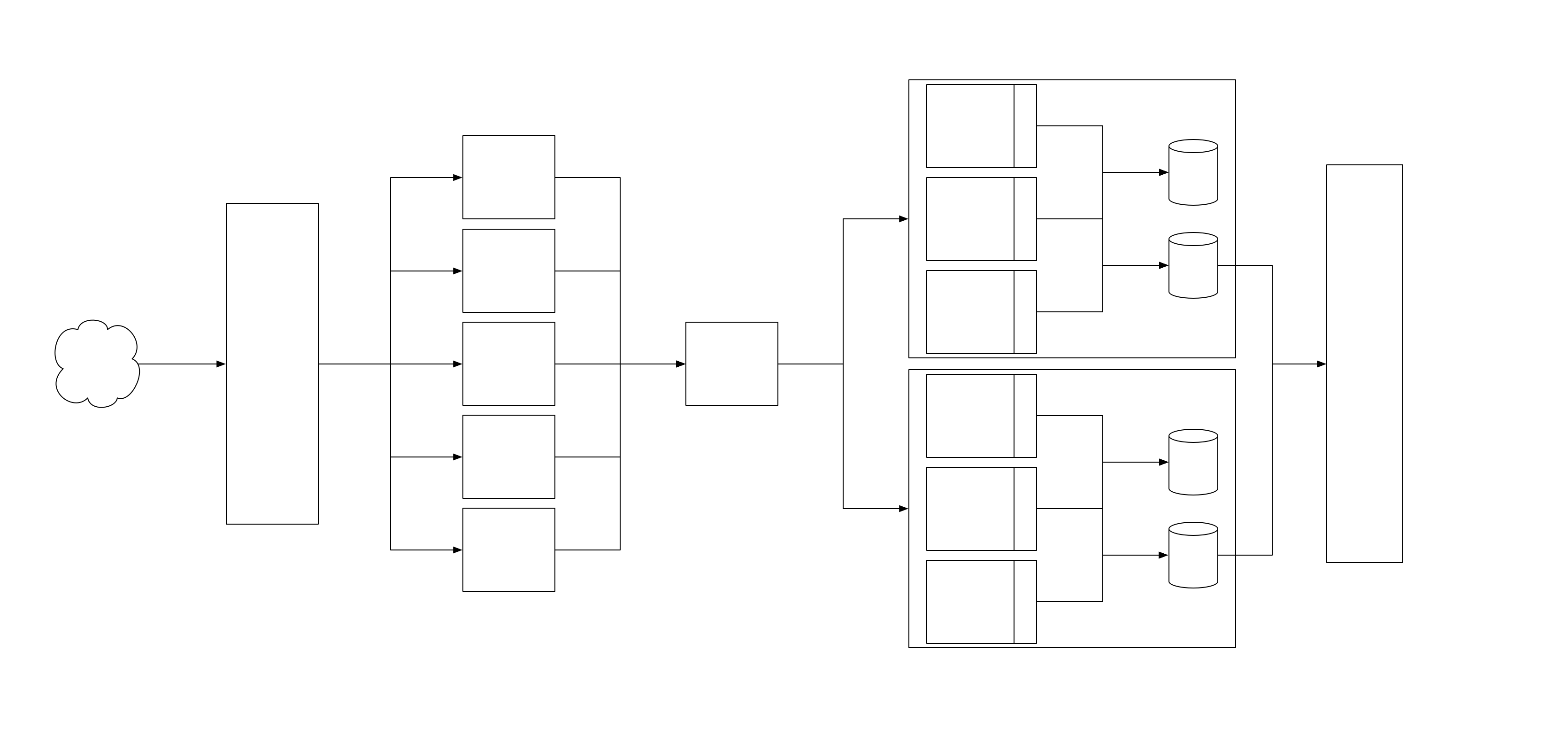
To minimize DynamoDB pricing, the Instacart team made several changes to their data model.
One was following the popular Single Table Design Pattern. DynamoDB does not support join operations so you should follow a denormalized model. Alex DeBrie (author of The DynamoDB book) wrote a fantastic article delving into this.
Another was changing the primary key to eliminate the need for a global secondary index (GSI).
With DynamoDB, you have to set a partition key for the table (plus an optional sort key). This key is used to shard your data into different partitions, making your DynamoDB table horizontally scalable. DynamoDB also provides global secondary indexes, so you can query and lookup items based on an attribute other than the primary key (either the partition key or the partition key + sort key). However, this would cost additional read/write capacity units.
To avoid this, Instacart changed their data model to eliminate the need for any global secondary indexes. They changed the primary key so it could handle all their queries.
They made the primary key a concatenation of the userID and the userType (gig worker or customer) and also added a sort key that was the notification’s ULID (time sorted and unique identifier). This eliminated the need for any GSIs.
Rollout and Results
To ease the transition, Instacart uses Dynamoid, a Ruby ORM for DynamoDB. They started the transition by rolling out dual writing (write notifications to both Postgres and DynamoDB).
Later, they added reads and were able to switch teams over from the Postgres codepath to DynamoDB.
Since the transition, more teams at Instacart have started using DynamoDB and features related to Marketing and Instacart Plus are now powered by DynamoDB. Across all the teams they now have over 20 tables.
For more details, check out the full blog post here.
How did you like this summary?Your feedback really helps me improve curation for future emails. |
Test out InfluxDB Cloud for Free
Working with large sets of time-stamped data has its challenges.
Fortunately, InfluxDB is a time series platform purpose-built to handle the unique workloads of time series data.
Using InfluxDB, developers can ingest billions of data points in real-time with unbounded cardinality, and store, analyze, and act on that data – all in a single database.
No matter what kind of time series data you’re working with – metrics, events, traces, or logs – InfluxDB Cloud provides a performant, elastic, serverless time series platform with the tools and features developers need. Native SQL compatibility makes it easy to get started with InfluxDB and to scale your solutions.
Companies like IBM, Cisco, and Robinhood all rely heavily on InfluxDB to build and manage responsive backend applications, to power predictive intelligence, and to monitor their systems for insights that they would otherwise miss.
See for yourself by quickly spinning up the platform and testing it out InfluxDB Cloud for free.
Tech Snippets



Quastor Pro
In addition to our emails, you can also get weekly articles on system design and technical dives on cool tech!
Past articles include
System Design Articles
Tech Dives
Database Concepts
It’s $12 per month and I’d highly recommend using your job’s Learning & Development stipend to pay for it!
How to use 1:1 Meetings to Propel Your Career
Rahul Pandey was a Tech Lead at Facebook and he’s the founder of Taro, a community for software engineers to share career advice.
He posted a fantastic video on tips for doing 1:1s effectively.
Here’s a summary
You should be having regular 1:1 meetings with your manager to discuss career growth, issues and provide feedback. These meetings are key to building trust in your relationship.
Pursue Awkward 1:1s
Mark Rabkin, a Vice President at Facebook, wrote a great article about making your 1:1 meetings awkward. You shouldn’t waste this time on topics that could easily be discussed in the open.
Instead, talk about things like
Meta & Feelings - Talk about emotions. Are there any fears you feel (around career, project, upcoming deadlines, etc.)? Discuss them.
Honest Feedback - Ask them how you can be better. Or, maybe there’s feedback they gave you in a performance review that you disagree with. Talk about that.
Seek Advice - Discuss a growth area you’re currently working on and ask for suggestions.
Embrace the concept of having an “awkward” 1:1 meeting with your manager.
Go Beyond Status Updates
It’s easy for weekly 1:1 meetings to devolve into what you did last week and your plans for this week.
Instead, you could think about your highlight and lowlight of the last week and share that with your manager, along with any associated feelings.
Another tactic is to share an observation about your environment/work and give your thoughts about it. You might talk about how everyone on the team shows up late to a certain meeting and that makes you feel like the team doesn’t find it useful and maybe it could be eliminated.
Write Down Takeaways
Many engineers don’t have a system to track the 1:1 discussions over time.
You should consistently be writing down meeting notes in a shared place that you and your manager have access to.
This will show your manager that you’re listening and that you care about what happens in the 1:1 meetings.
It will also give your manager a clear view of your progression over time. This can be very useful for performance reviews.
You can view the full video here.
How did you like this summary?Your feedback really helps me improve curation for future emails. Thanks! |