How Stripe synchronizes time across their distributed system
How Stripe uses physical and logical clocks for keeping time. Plus, a deep dive on caching in system design, how eBay uses LLMs to improve developer productivity and more.
Arpan KG
October 28, 2024
Hey Everyone!
Today we’ll be talking about
How Stripe tracks Time in their Billing System
Common misconceptions developers have around keeping time
Physical clocks with NTP and PTP
Logical clocks with Lamport/Vector clocks
How Stripe uses physical and logical clocks in their billing system
Tech Snippets
Deep Dive on Caching in System Design
How eBay uses LLMs to improve developer productivity
How Eventbrite defends against CSRF
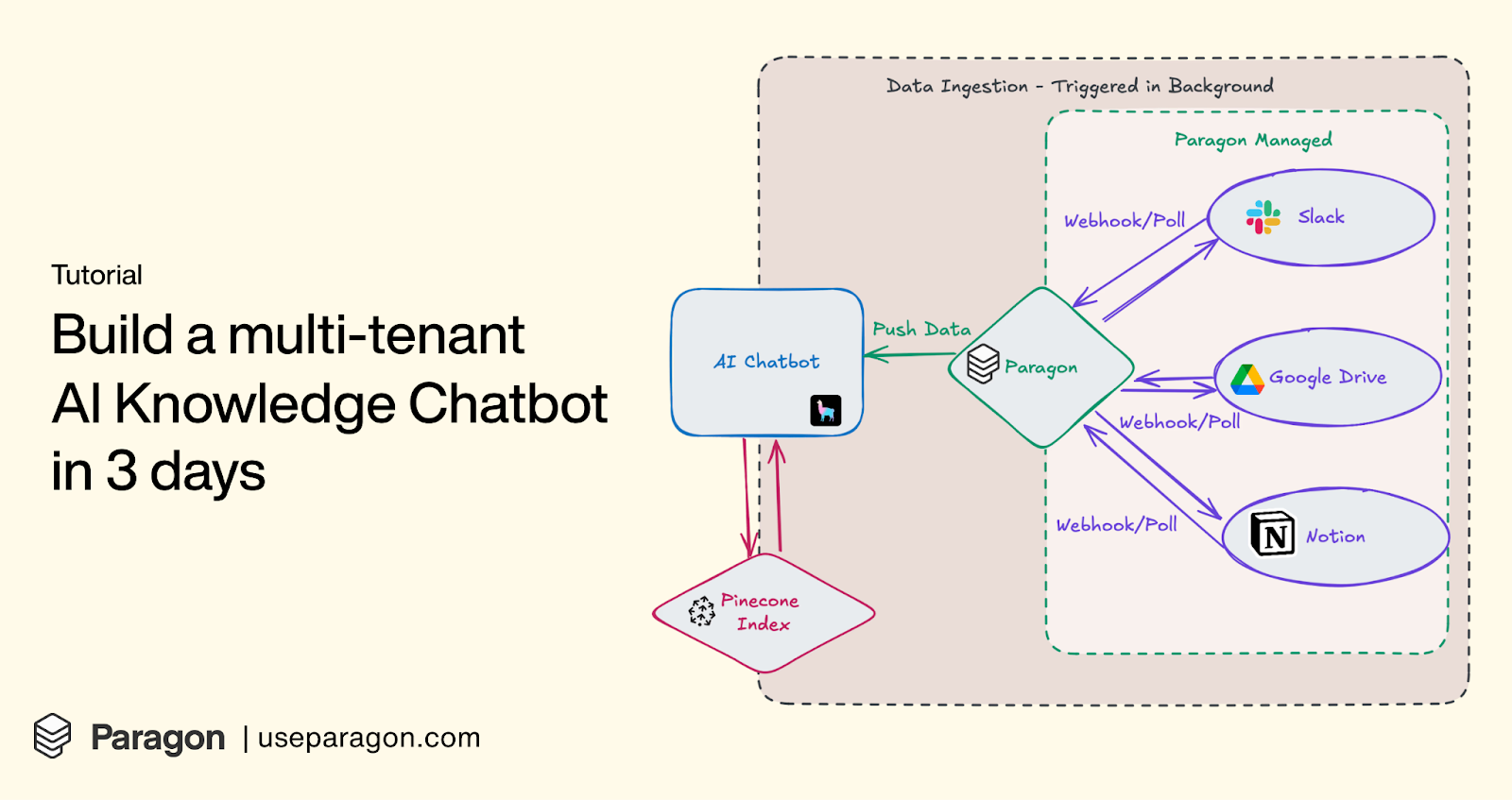
Everyone is building gen-AI features into their product these days, and chatbots are almost always the starting point.
If your product team is asking you to build an AI chatbot that is context-aware of your users’ external data (from Google Drive files, Slack messages, Jira tickets, etc.), this tutorial is for you.
It walks through the architecture and implementation of the RAG chatbot, with example integrations and data ingestion pipelines for Slack messages, Google Drive files, and Notion pages, using the following tools:
Llama-index for the front-end and RAG orchestration
Pinecone as the vector store
Paragon as the integration & data ingestion infrastructure
sponsored
How Stripe tracks Time in their Billing System
Stripe is one of the largest payment processors in the world with over 2 million customers on the platform. In 2023, they processed over $1 trillion of payment volume.
Their core product is an API that you can integrate into your application to easily charge your users on a one-time or subscription basis.
As with any distributed system, maintaining the correct time is extremely important for all the servers in Stripe’s backend. They need to make sure that events are correctly ordered and that the time on every server is accurate.
Any errors in Stripe’s timekeeping will lead to refunds, credit card disputes and angry users.
In this article, we’ll talk about two commonly-used methods for time-keeping in distributed systems: physical clocks and logical clocks.
We’ll give an overview of both algorithms and talk about how Stripe uses them in their billing system.
Common Misconceptions about time
If you want a quick idea of how hard measuring time is, this is a good list of edge cases you’ll have to deal with.
When working with time, many developers make false assumptions like:
Days always have 24 hours - due to daylight savings time changes, some days will have 23 or 25 hours.
Computer clocks are accurate - computers use quartz clocks which are prone to clock skew. They can add or lose seconds over the course of a day.
Time Zones are Static - due to daylight savings time changes, the time difference between countries will change.
A timestamp represents the time that the event occurred - the timestamp could represent the time right after the event ended. Or it could represent the time right before the event started. It could also be a few milliseconds off from when the event occurred.
and many more.
When you’re building a distributed system, you’ll have to think about how to handle many of these different edge cases.
Ways of Measuring time in a Distributed System
As mentioned earlier, there’s two main methods for keeping track of time: physical clocks and logical clocks.
Physical Clocks
When people think about keeping track of time, they’re usually thinking of physical clocks. This is where you rely on the internal quartz clock within the server to keep track of the real-world time (5/16/24 16:18:26 or 1715876326 if you’re using a Unix timestamp).
The issue with physical clocks is that they become inaccurate due to clock drift. Quartz clocks will gain/lose seconds per day so your machines will quickly become unsynchronized.
You solve this by synchronizing the clocks in your machine with a time server (machine synchronized with an atomic clock or some other time source) every few minutes.
Protocols that help you do this include Network Time Protocol (NTP) and Precision Time Protocol (PTP).
To learn more about physical clocks, I’d highly recommend checking out this lecture by Martin Kleppman (author of Designing Data Intensive Applications).
Logical Clocks
On the other hand, logical clocks focus on ordering events without using any physical time. They track the sequence in which events have occurred in your system. This makes them extremely useful for capturing causal relationships between the events in your backend.
A common example of a logical clock is when you’re using transaction IDs to order transactions. Anytime there’s a new transaction, it gets assigned a new transaction ID. The IDs are monotonically increasing (0, 1, 2, 3 ,… for example) so you can compare two transaction IDs to figure out which transaction happened earlier. You can do this without relying on timestamps generated by a physical clock.
Two common algorithms for implementing logical clocks are Vector Clocks and Lamport Clocks.
Martin Kleppmann has another terrific lecture delving into logical clocks that you can view here.
Timekeeping at Stripe
As you might guess, Stripe uses both physical and logical clocks throughout their backend.
However, they also use hybrid logical clocks. This is where you integrate physical timestamps (from real-world clocks) with ordered events from logical clocks.
Stripe published a really interesting blog post delving into how they implemented this for their billing system.
Customers on Stripe need a way to double-check that their billing setup is working correctly and they don’t have bugs in their implementation. To help them do this, Stripe has a feature where they can simulate the passage of time and see what happens during important future events (when a trial ends, a subscription is updated, invoice is charged, etc.)
These events in Stripe’s system will have both a physical timestamp and a logical timestamp. The physical timestamp represents the exact time when the event happens by the second/hour/day/month/year while the logical timestamp represents the order of events.
The logical timestamp lets Stripe “fast-forward” through events and simulate what happens based on causality.
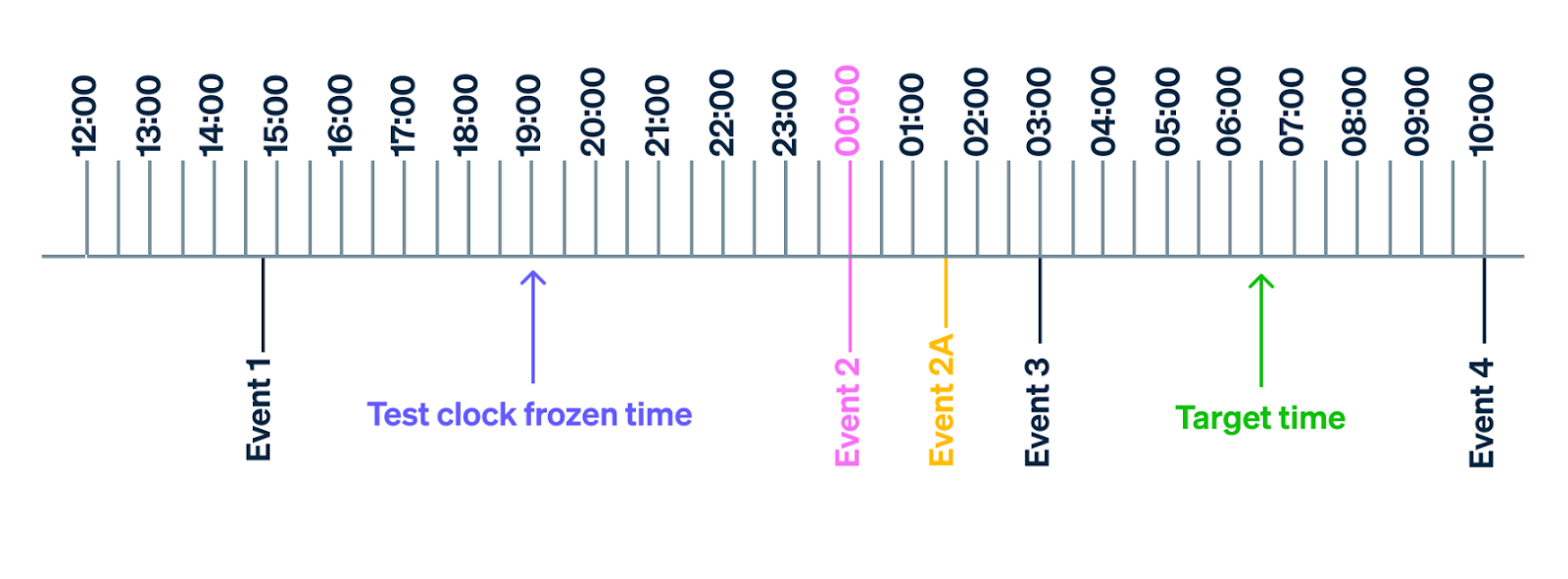
Stripe created an abstract “time provider” service that would send timestamps that were backed by a real-world clock or by a test clock.
When a user needs to test the billing service and ensure it would work properly up to a future time, Stripe will use a logical clock to compute all the next meaningful events (trial end timestamp, subscription update timestamp, etc.) until that future time.
Then, the test clock time will be updated to the timestamps for all the meaningful events between the current time and the target time so the system can check that they’re billed properly.
Everyone is building gen-AI features into their product these days, and chatbots are almost always the starting point.
If your product team is asking you to build an AI chatbot that is context-aware of your users’ external data (from Google Drive files, Slack messages, Jira tickets, etc.), this tutorial is for you.
It walks through the architecture and implementation of the RAG chatbot, with example integrations and data ingestion pipelines for Slack messages, Google Drive files, and Notion pages, using the following tools:
Llama-index for the front-end and RAG orchestration
Pinecone as the vector store
Paragon as the integration & data ingestion infrastructure
sponsored
