How Airbnb Processes a Million User Events Every Second
An introduction to Apache Flink, the Lambda Architecture and the Architecture of Airbnb's platform. Plus, how Duolingo cut their AWS bill by 20%, Google's State of the Art Quantum chip and more.
Hey Everyone!
Today we’ll be talking about
How Airbnb Processes a Million User Events Every Second
How Airbnb built a User Events Platform to track, process and store billions of user interactions
Introduction to the Lambda Architecture
Overview of Apache Flink
The Architecture of Airbnb’s User Events Platform
Tech Snippets
Breaking down the Browser Rendering Process
How to Maintain Code Quality in the age of AI
How Duolingo cut their Cloud Spend by 20%
Explaining the Modular Monolith Architecture
Google’s State of the Art Quantum Chip
The Architecture of Airbnb’s User Signals Platform
Airbnb is one of the largest travel platforms in the world with over 200 million active users. When travelers browse through the app, there are millions of properties/destinations that Airbnb can recommend. Small improvements in their recommendation system can result in a huge increase in bookings (and hundreds of millions of dollars in revenue)
To provide the best recommendations, Airbnb needs to keep track of past user actions like viewing listings, favoriting experiences, starting a booking process, etc. This data needs to be processed, cleaned and stored in a database.
The Airbnb team built the User Signals Platform to handle this. It ingests and processes over 1 million user events per second and stores them in a key-value database. The platform serves over 70k+ queries per second to other internal teams at Airbnb that need access to this data.
Last week, the Airbnb engineering team published a terrific blog post delving into how they built this platform and the design choices they made.
User Signal Platform Goals
The Airbnb team had quite a few objectives for the User Signals Platform. Some of the goals were:
Ingest Real-time and Historical User Data - The platform should store real-time user engagement data as it occurs, but it should also allow for batch jobs that write historical user engagement data.
Low Latency - Other services at Airbnb will be relying on the User Signals Platform for real-time user engagement data, so the platform should ingest and process new user events in under 1 second.
Asynchronous Computation - Engineers at Airbnb should be able to run asynchronous computation jobs on the data in the User Signals platform to generate deeper insights.
In this article, we’ll talk about the architecture of the User Signals Platform and also delve into the design patterns and technologies Airbnb used.
Introduction to Lambda Architecture
The core design pattern Airbnb used for their platform is the Lambda Architecture. The Lambda architecture is composed of two layers:
Speed/Streaming Layer (Real-Time): Processes streaming data as it arrives, delivering low-latency, up-to-date results. Airbnb implements this with Apache Flink and achieves latencies less than one second.
Batch Layer (Offline): Periodically processes large volumes of historical data to generate more accurate or corrected views. The batch layer ensures long-term accuracy and handles late-arriving data or retrospective fixes. The batch layer will typically operate on a longer timescale, updating views every few hours.

By combining these two layers, the Lambda architecture provides the best of both worlds. The speed layer ensures fresh, low-latency data for online queries and personalization. The batch layer ensures correctness, allowing retrospective updates and improvements to data quality.
Introduction to Apache Flink
The core technology Airbnb used for their User Signals Platform is Apache Flink, an open source engine built for processing real-time data with very low latency.
Prior to Flink, data processing systems would rely on “micro-batching” to process data in “real-time”. They would collect data over a small fixed period (every few seconds/minutes) and then process that data as a batch job.
On the other hand, Flink takes an event-driven approach. Instead of waiting for a batch window to fill up, Flink processes each event as soon as it arrives. This results in much lower latencies.
Another benefit of Flink is that it is stateful. Traditional data processing systems might require an external database to maintain state across events. Flink integrates state management directly into the engine, allowing it to remember, accumulate, and update contextual information as events stream in. This is great if you want to do operations like aggregations or joins across your messages.
Other benefits of Apache Flink are:
Fault Tolerance - Flink provides checkpointing mechanisms to ensure that, if a job or node fails, the system can recover to a previously consistent state. This guarantees exactly-once processing, so each event is reflected in the application’s state exactly once, even in the face of failures.
Understanding Event-Time - Flink understands the concept of “event time“ (the time when an event actually occurred) instead of just processing time (when the event is processed by the system). This makes it much easier to handle out-of-order events or late-arriving data accurately.
Integration with the Ecosystem - Flink is widely used and comes with connectors to all the other data tools you might be using (Kafka, Postgres, S3, etc.)
Architecture of Airbnb’s User Signals Platform
Here’s the architecture of Airbnb’s User Signals Platform
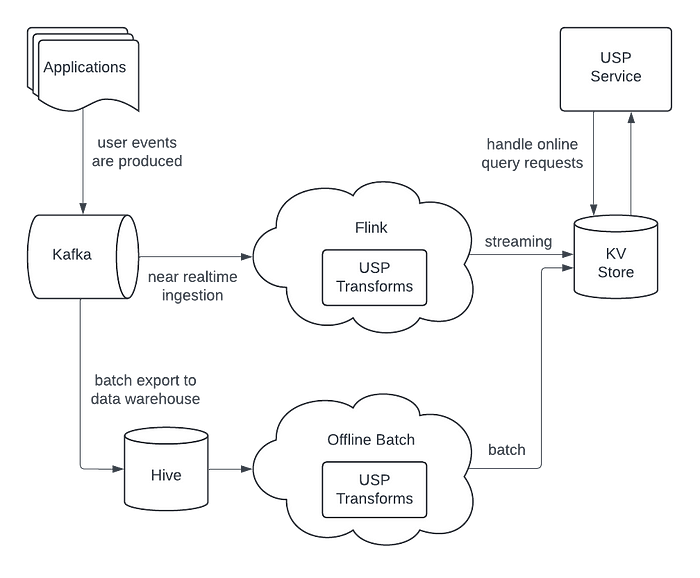
As mentioned earlier, it’s based on the Lambda Architecture, so it consists of a real-time ingestion layer and a batch layer.
Here are the steps:
User Events: Guests interacting with Airbnb’s apps generate raw events when they view properties, add an experience to their wishlist, search for “rooms in London”, etc.
Real-Time Transformation (Speed Layer): Events flow into Kafka, where Flink jobs consume and transform them into “User Signals.” Some transformations are just simple mappings from raw events, while others may require joining multiple events based on user ID to create richer signals.
KV Storage and Serving: The transformed User Signals are stored in a Key-Value store with append-only writes. Using append-only writes helps ensure idempotency and makes data operations much simpler.
Batch Processing (Batch Layer): Periodic batch jobs will reprocess the historical data sets and identify any discrepancies or missed events from the speed layer. They’ll backfill the missing/incorrect data to ensure long-term data accuracy and consistency.
Asynchronous Computations: In addition to the immediate user signals that are stored in the KV store, Airbnb has Flink jobs that consume the new user signals to generate more insights. These jobs do things like categorize users into segments or group a single user’s actions into “sessions” to get a better understanding of the user’s intent. These jobs are run asynchronously.
Online Queries and Services: The USP service provides a way for downstream services at Airbnb to use the user signals data for their own insights.
Results
With this setup, the User Signals Platform processes over 1 million events per second across 100+ Flink jobs. The USP service serves over 70k queries per second to various teams/services at Airbnb.




