How Grab uses Graph Databases to Reduce Fraud
Plus, Tips on Negotiating Compensation for Software Engineers from a Principal Engineer at Amazon
Hey Everyone!
Today we'll be talking about
How Grab built their Graph-based Prediction System to Minimize Fraud
Grab is a “super-app” in Southeast Asia with millions of daily users
They built a system using AWS Neptune, Graph Convolutional Networks and Autoencoders to identify fraudulent users and transactions
Graphs are data structures for representing relationships in data with nodes and edges
Popular graph databases include AWS Neptune, Neo4j, ArrangoDB and more
Grab uses a combination of semi-supervised and unsupervised learning algorithms to identify fraud
Tips on Negotiating Compensation for Software Engineers
Steve Huynh is a Principal Engineer at Amazon and he made a great video with tips on negotiating compensation
Rather than just asking for more money, you can start the conversation by discussing expectations and outcomes for the role
Understand what are your alternatives and what are the company’s alternatives. Many recruiters may try to create a false “sense of scarcity“ around the offer.
Over-communicate with your managers. Send a weekly state of me email to your manager and skip-manager discussing your accomplishments and priorities.
Tech Snippets
Things More Developers Should Know About Databases
Rules of Thumb for Software Development Estimations
Real World Recommendation Systems
Linux from Scratch
Practical Cryptography for Developers
How Grab uses Graphs for Fraud Detection
Grab is a “super-app” that offers ride-sharing, food delivery, financial services and more in Singapore, Malaysia, Vietnam and other parts of Southeast Asia.
It’s one of the most valuable technology companies in the world with millions of people using the app every day.
One of the benefits of being a “super-app” is that you can make significantly more money per user. Once someone signs up to Grab for food-delivery, the app can direct them to also sign up for ride-sharing and financial services.
The downside is that they have to deal with significantly more types of fraud. Professional fraudsters could be setting up exploiting promotional offers, defrauding Grab’s insurance services, laundering money, etc.
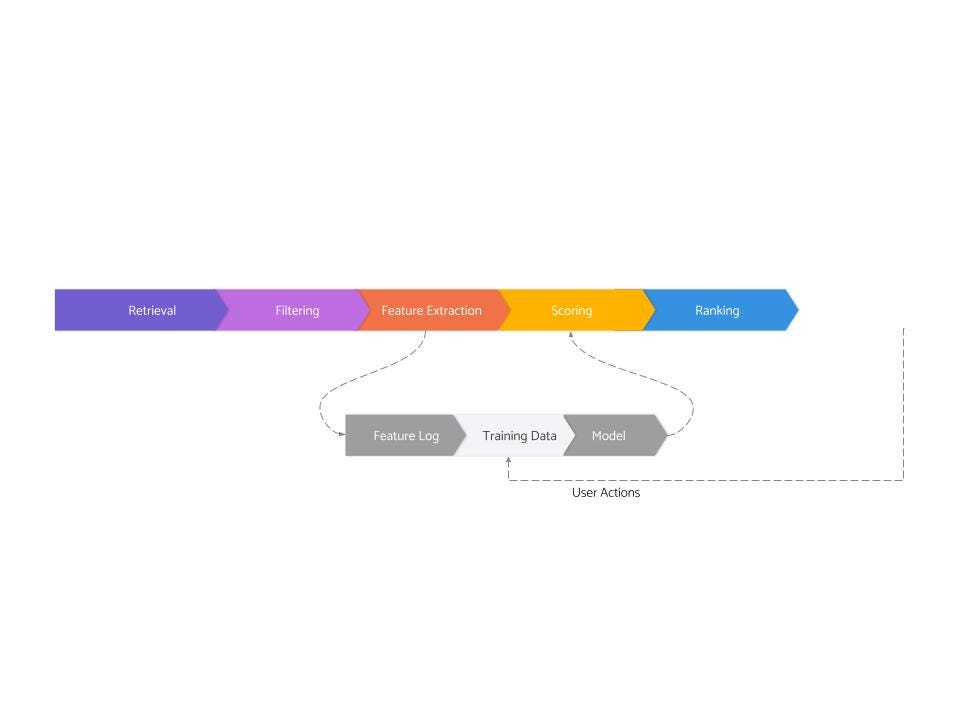
To quickly identify and catch scammers, Grab invests a large amount of engineering time into their Graph-based Prediction platform.
This prediction platform is comprised of many different components
Graph Database
Graph-based Machine Learning Algorithms
Visualizing Nodes and Connections
We’ll delve into each of these and talk about how Grab built it out.
Grab wrote a fantastic 5 part series on their engineering blog on exactly how they built this platform, so be sure to check that out.
Introduction to Graphs
Graphs are a very popular way of representing relationships and connections within your data.
They’re composed of
Vertices - These represent entities in your data. In Grab’s case, vertices/nodes represented individual users, restaurants, hotels, etc. Each vertice has a large amount of features associated with it. For example, a user node might also have a home address, IP address, credit card number, etc.
Edges - These represent connections between nodes. If a customer ordered some Hainanese chicken rice from a restaurant through Grab delivery, then there would be an edge between that customer and the restaurant. If two customers have the same home address, then there could be an edge connecting them.
If two nodes have an edge between them, then we say that these nodes are neighbors or that they’re adjacent.Weights - These represent the strength or value of an edge. In Grab’s case, a weight might indicate the transaction amount or frequency of interactions between two nodes. If I’m ordering halo-halo from an ice cream store every night, then the weight between me and the ice cream store would be very large.
Direction - Edges between nodes can be directed or undirected. A directed edge means the relationship is one-way while an undirected edge means a bi-directional relationship. WIth Grab, a food order might be represented with a directed edge from the user to the restaurant while a common IP address could be represented with an undirected edge between two users.

Once you have your data represented as a graph, there’s a huge range of graph algorithms and techniques you can use to understand your data.
If you’d like to learn more about graphs and graph algorithms then I’d highly recommend this youtube playlist by William Fiset.
Graph Databases
You may have heard of databases like Neo4j, AWS Neptune or ArangoDB. These are NoSQL databases specifically built to handle graph data.
There’s quite a few reasons why you’d want a specialized graph database instead of using MySQL or Postgres.
Faster Processing - Relational databases will use joins to traverse relationships between nodes. This can quickly become an issue, especially for finding deep relationships between hundreds/thousands of nodes. On the other hand, graph databases use pointers to traverse the underlying graph. These act as direct pathways behind nodes, making it much more efficient to traverse.
Each node has direct references to its neighbors (called index-free adjacency) so traversing from a node to its neighbor will always be a constant time operation in a graph database.Graph Query Language - Writing SQL queries to find and traverse edges in your graph can be a big pain. Instead, graph databases employ query languages like Cypher and Gremlin to make queries much cleaner and easier to read.
Here’s a SQL query and an equivalent Cypher query to find all the directors of Keanu Reeves movies.
SQL query

Cypher Query
Algorithms and Analytics - Graph databases will come integrated with commonly used algorithms like Djikstra, BFS/DFS, cluster detection, etc. You can easily and quickly runs tasks for things like
Path Finding - find the shortest path between two nodes
Centrality - measure the importance or influence of a node within the graph
Similarity - calculate the similarity between two nodes
Community Detection - evaluate clusters within a graph where nodes are densely connected with each other
Node Embeddings - compute vector representations of the nodes within the graph
Grab uses AWS Neptune as their graph database.
Machine Learning Algorithms on Graphs at Grab
For fraud detection, Grab uses a combination of semi-supervised and unsupervised machine learning algorithms on their graph database. We’ll go through both.
Semi-Supervised ML
Grab uses Graph Convolutional Networks (GCNs), one of the most popular types of Graph Neural Network.
You may have heard of using Convolutional Neural Networks (CNNs) on images for things like classification or detecting objects in the image. They’re also used for processing audio signals (speech recognition, music recommendation, etc.), text (sentiment classification, identifying names/places/items), time series data (forecasting) and much more. CNNs are extremely useful in extracting complex features from input.
With Graph Convolutional Networks, you go through each node and look at its edges and edge weights. You use these values to create an embedding value for the node. You do this for every node in your graph to create an embedding matrix.
Then, you pass this embedding matrix through a series of convolutional layers, just as you would with image data in a CNN. However, instead of spatial convolutions, GCNs perform graph convolutions. These convolutions aggregate information from a node's neighbors (and the neighbor’s neighbors, and so on), allowing the model to capture the local structure and relationships within the graph.
At Grab, they use a specific type of GCN called a Relational Graph Convolutional Network (RGCN). This model is designed to handle graphs where edges have different types of relations. Grab might have a “has ordered from” edge between a customer and a restaurant or a “shares home address” edge between two customers. These relationships will be treated differently by the RGCN.
They train the RGCN model on a graph with millions of nodes and edges, and have it output a fraud probability for each node.

A huge benefit with using neural networks on Graphs is that they usually come with great explainability. Unlike many other deep network models, you can visualize the output and understand why the model is classifying a certain node as fraudulent.
Unsupervised Learning
Grab also makes heavy use of unsupervised learning. These are essential for picking up new patterns in the data that the company’s security analysts haven’t seen before.
Fraudsters are always coming up with new techniques in response to Grab’s countermeasures, so unsupervised learning helps pick up on new patterns that Grab didn’t know to search for.
One way Grab models the interactions between consumers and merchants as a bipartite graph.
This is a commonly-seen type of graph where you can split your nodes into two groups, where all the edges are from one group to the other group. None of the nodes within the same group are connected to each other.

You can see the graph in the image on the left. One group only has customer nodes whereas the second group only has merchant nodes.
Grab has these node/merchant nodes as well as rich feature data for each node (name, address, IP address, etc.) and edge (date of transaction, etc.).
The goal of their unsupervised model is to detect anomalous and suspicious edges (transactions) and nodes (customers/merchants).
To do this, Grab uses an autoencoder, called GraphBEAN.
An autoencoder is a neural network that has two main parts
Encoder - take in the input and compress it into a smaller representation. This compressed version is called a latent space
Decoder - Take the compressed representation and reconstruct the original data from it
You train the two parts of the autoencoder neural network to minimize the difference between the original input into the encoder and the output from the decoder.
Autoencoders have many use cases, but one obvious one is for compression. You might take an image and compress it with the encoder. Then, you can send it over the network. The recipient can get the compressed representation and use the decoder to reconstruct the original image.
Another use case where autoencoders shine is with anomaly detection.
The idea is that normal behaviors can be easily reconstructed by the decoder. However, anomalies will be harder to reconstruct (since they’re not as represented in the training dataset) and will lead to a high error rate.
Any parts of the graph that have a high error rate when reconstructed should be examined for potential anomalies. This is the strategy Grab uses with GraphBEAN.

GraphBEAN has an encoder and two decoders.
The model takes the bipartite graph as input. The encoder runs the graph through several graph convolution layers to create the compressed representation.
Then, the compressed representation is given to the two decoders: the feature decoder and the structure decoder.
Feature Decoder - this neural net tries to reconstruct the original graph’s nodes and edges using a series of graph convolutional layers.
Structure Decoder - this tries to learn the graph structure by predicting if there will be an edge between two nodes. It generates predictions for whether or not there will be a connection between a certain consumer/merchant pair.
The output from the Feature Decoder and Structure Decoder is taken and then compared with the original bipartite graph.
They look for where the decoders got the structure wrong and use that to compute an anomaly score for each node and edge in the graph.
This score is used to flag potential fraudulent behavior. Fraud experts at Grab can then investigate further.
To get all the details, read the full series on the Grab Engineering blog here.
How did you like this summary?Your feedback really helps me improve curation for future emails. |
Tech Snippets
Tips on Negotiating Compensation
Steve Huynh is a Principal Engineer at Amazon and he runs an awesome YouTube channel called A Life Engineered.
Recently, he published a fantastic video delving into tips on negotiating compensation where he talked with Brian Liu. Brian runs a startup that negotiates compensation on behalf of software engineers.
Here’s a summary of the main takeaways from the video.
Focus on how you can create value for the company
Many people think of negotiating as just telling your recruiter “I have another offer that is paying me $xyz more, so plz match“.
Instead, Brian suggests you start by creating a document that outlines expectations and outcomes for the role. The goal is to do this when you get the offer and to do it with your potential manager.
This aligns expectations and shows your manager that you’re focused on meeting their needs. After doing this, it’s easier to ask for the extra compensation you’re looking for.
Brian talks about how he had a client who was originally given an L62 offer at Microsoft (mid-level engineer offer).
Rather than trying to negotiate with the recruiter, the engineer talked to his future manager and discussed expectations and deliverables for the role. He was able to make a case for L63 (senior software engineer) impact and offered to do additional interviews to prove he was capable.
The entire process took an additional month but he was able to get his level and compensation increased to L63, which accelerated his career by 1-2 years.
Understand BATNA
BATNA stands for Best Alternative to a Negotiated Agreement. It just means your alternative if the current offer doesn’t work out.
The best negotiators will obviously work to strengthen their own BATNA (get other high-paying offers) but they’ll also understand the target company’s BATNA. What other options does the company have if you reject the offer?
Many recruiters are trained to create as much “scarcity” as possible around the offer. They might tell you the offer won’t last, hint at imminent rounds of fundraising which could dilute your equity, etc.
Instead, you should try to have an abundance mindset. Understand exactly how much time you have to look for an offer (what is your financial status) and don’t just settle for an offer where you’re down-leveled/underpaid out of fear.
Of course, if you’re in a precarious financial situation then perhaps you should just take the offer, but then it might make sense to stay on the market and continue looking if you’re severely underpaid/under-leveled.
Your work will not speak for itself
This is advice geared towards being on the job. You have to understand that solely doing good work is not enough. You need to have a strategy for how you communicate your accomplishments with your manager.
It’s impossible for your manager/skip-manager to have a total understanding of what you’re doing all-day. They obviously have their own tasks and priorities.
Instead, Brian advocates sending your manager and skip-manager a weekly state of me email.
In this, you discuss
What have you accomplished over the past week
Where are you currently blocked
What are your priorities for the next week
Doing this will help you stay on the radar of the people who decide your future promotions and compensation.
Also, you should make sure you’re creating a brag document. Make sure that your manager knows what you’ve achieved over the last quarter.
However, don’t just summarize your work in the brag document.
Instead, you should distill
What do your manager care about?
What does your skip manager care about?
Find the most critical accomplishments you did that your manager cares the most about and ensure that it’s communicated.
For more details, watch the full video here.
How did you like this summary?Your feedback really helps me improve curation for future emails. Thanks! |