How Etsy Scaled Their Database
Plus MIT's latest Intro to Deep Learning course, Logical Clocks in Distributed Systems, Twitter's Rec Algorithm and more.
Arpan KG
April 04, 2023
Hey Everyone!
Today we’ll be talking about
Sharding MySQL at Etsy
In 2021, Etsy migrated 23 tables (over 40 billion rows) from MySQL to Vitess (an open source, managed sharding solution for MySQL)
Changing the Data Model to make Sharding Easier
Building Confidence in the Data Migration Process
Dealing with Potential Issues in the Migration
Tech Snippets
MIT’s Introduction to Deep Learning course - Recurrent Neural Networks, Transformers and Attention
How to be a -10x Engineer
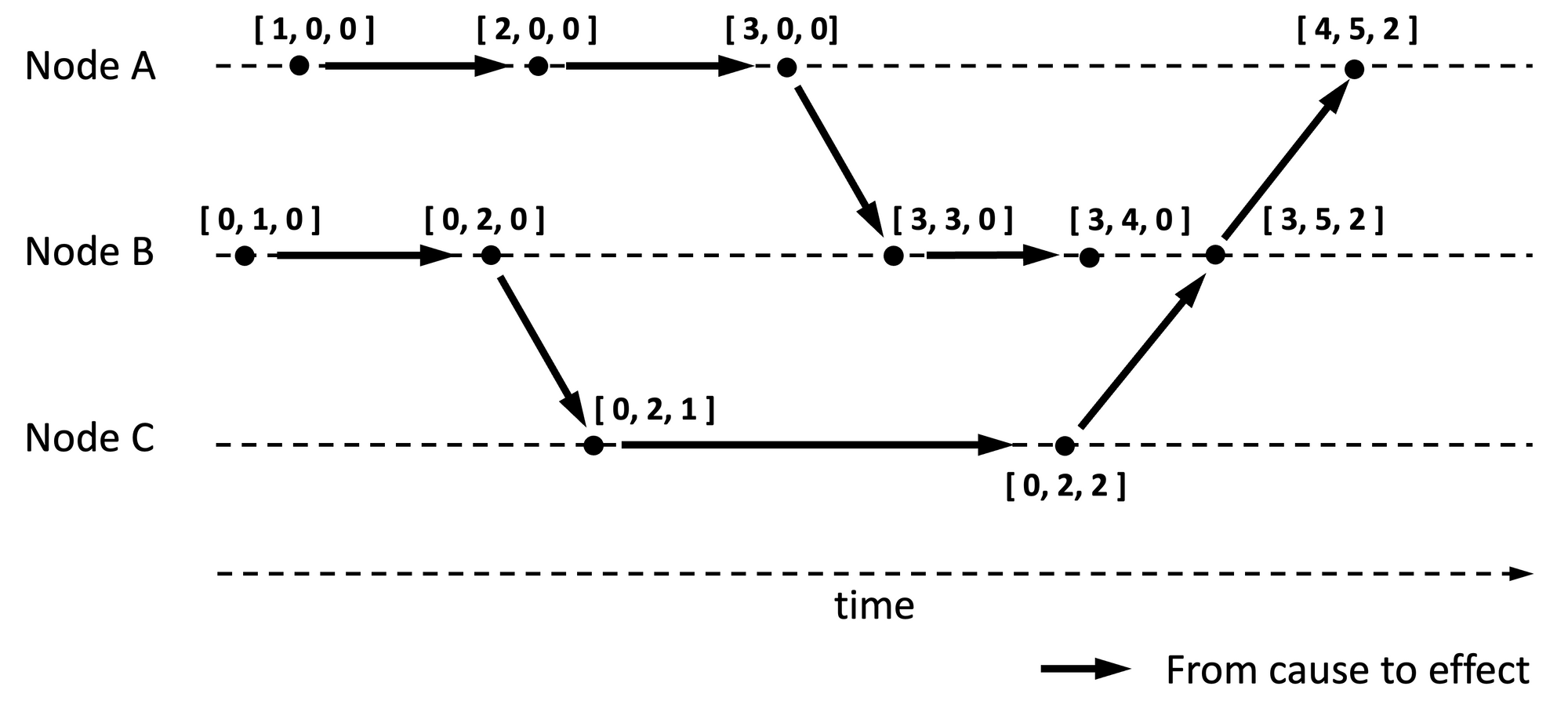
Logical Clocks in Distributed Systems
Dealing with Collisions in Hash Tables
Twitter’s Recommendation Algorithm
Database Sharding at Etsy
Etsy is a popular online marketplace for handmade, vintage items, and craft supplies with millions of active buyers and sellers. In 2020, they experienced massive growth, and by the end of the year, their payments databases urgently needed horizontal scaling as two of their databases were no longer vertically scalable (they were already on the highest resource tier on GCP). Additional spikes in traffic could lead to performance issues or loss of transactions so Etsy needed a long term solution to fix this.
To tackle this issue, Etsy spent a year migrating 23 tables (with over 40 billion rows) from four payments databases into a single sharded environment managed by Vitess. Vitess is an open-source sharding system for MySQL, originally developed by YouTube.
Etsy software engineers published a series of blog posts discussing the changes they made to the data model, the risks they faced, and the process of transitioning to Vitess.
Ideal Model
When sharding, the data model plays a crucial role in how easy implementation will be. The ideal data model is shallow, with a single root entity that all other entities reference via foreign key. By sharding based on this root entity, all related records can be placed on the same shard, minimizing the number of cross-shard operations. Cross-shard operations are inefficient and can make the system difficult to reason about.
For one of the databases, Etsy’s payments ledger, they used a shallow data model. The Etsy seller’s shop was the root entity and the team used the shop_id as the sharding key. By doing this, they were able to put related records together on the same shards.

Non-Ideal Model
However, Etsy's primary payments database had a complex data model that had grown/evolved over a decade to accommodate changing requirements, new features, and tight deadlines.
Each purchase could be related to multiple different shops/customers and payments were linked to various transaction types (Credit Card, PayPal, etc,). This made it challenging to shard.
The use of shop_id as the sharding key would have dispersed the data around a single payment across many different shards.

Etsy had two options to deal with this
Option 1 - Modify the structure of the data model to make it easier to shard. They considered creating a new entity called Payment that would group together all entities related to a specific payment. Then, they would shard everything by the payment_id to enable colocation of related data.
Option 2 - The second approach was to create sub-hierarchies in the data and then shard these smaller groups. They would use a transaction’s reference_id to shard the Credit Card and PayPal Transaction data. For payment data, they would use payment_id. After, the team would identify transaction shards and payment data shards that were related and collocate them.
The team found Option 2 to be faster to implement so they went with that. Using the already established primary keys to shard was much easier than changing the data model.

Additionally, Vitess has re-sharding features that make it easy to change your shard decisions in the future. Sharding based on the legacy payments data model was not a once-and-forever decision.
The Data Migration Process
After choosing the sharding method, Etsy had to migrate the data over to Vitess. They needed to have extreme confidence in the migration process and ensure that the system would function effectively after the switch.
Therefore, the team spun up a staging environment so they could test their migration process and run through it several times to find any potential issues/unknowns.
The engineers created 40 Vitess shards and used a clone of the production dataset to run through mock migrations. They documented the process and built confidence that they could safely wrangle the running production infrastructure.
They also ran test queries on the Vitess system to check behavior and estimate workload and then used VDiff to confirm data consistency during the mock migrations. VDiff lets you compare the contents of your MySQL tables between your source database and Vitess. It will report counts of missing/extra/unmatched rows.
To migrate the data from the source MySQL databases to sharded Vitess, the team relied on VReplication. This sets up streams that replicate all writes. Any writes to the source side would be replicated into the sharded destination hosts.
Additionally, any writes on the sharded replication side could be replicated to the source database. This helped the Etsy team have confidence that they could switch back to the original MySQL databases if the switchover wasn’t perfect. Both sides would stay in sync.
Potential Issues
During the migration mocks, the Etsy team found several challenges. They talked about these potential pitfalls and how they mitigated them.
Reverse VReplication Breaking - As mentioned previously, reverse VReplication meant that any changes on sharded MySQL would be written back to the original MySQL databases. This gave the Etsy team confidence that they could switch back if there were issues. However, this broke several times due to enforcement of MySQL unique keys. In the sharded database, unique keys were only enforcing per-shard uniqueness. This created a problem when VReplication attempted to write those rows back to the unsharded database and the unique keys would collide causing one of the writes to fail. They solved this problem by using Vitess’ solution for enforcing global uniqueness.
Scatter Queries - If you don’t include the sharding key in the query, Vitess will default to sending the query to all shards (a scatter query), This can be quite expensive. If you have a very large codebase with many types of queries, it can be easy to overlook adding the shard key to some and have a couple of scatter queries slip through. Etsy was able to solve this by configuring Vitess to prevent all scatter queries. A scatter query will only be allowed if it includes a specific comment in the query, so that scatter queries are only done intentionally.
In the end, the team was able to migrate over 40 billion rows of data to Vitess. They were able to reduce the load on individual machines massively and gave themselves room to scale for many years.
For more details, you can check out the full posts here.
How did you like this summary?Your feedback really helps me improve curation for future emails. |