The Engineering behind Instagram's Recommendation Algorithm
Plus, 5 properties of healthy software projects. Writing a toy compiler with Go and LLVM and more.
Hey Everyone!
Today we'll be talking about
The Engineering Behind Instagram’s Recommendation Algorithm
The Candidate Generation/Retrieval Phase
Two Tower Neural Network Models and Why They’re Highly Scalable
First Pass Ranking With a Two Tower Model
Second Pass Ranking With a Multi-Task Multi-Label Model
Tech Snippets
Writing a Toy Compiler With Go and LLVM
A curated list of Software and Architecture Design Patterns
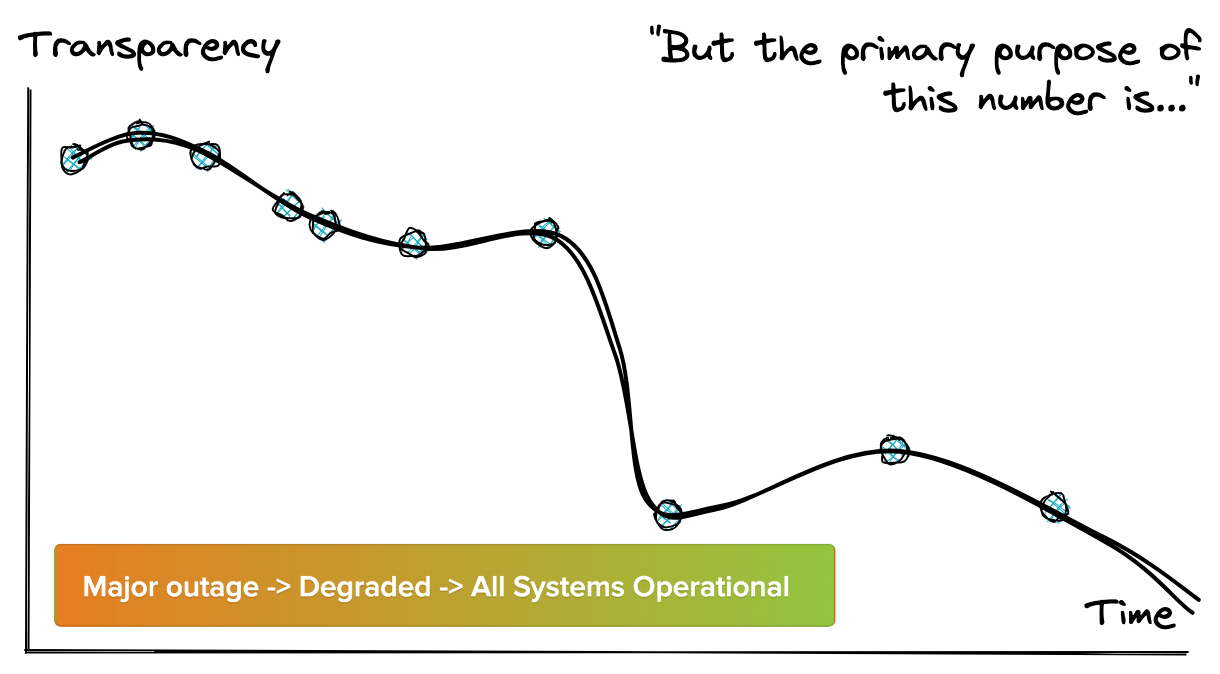
Build a More Transparent Uptime Page
5 Properties of Healthy Software Projects
OKRs are not OK
The Engineering Behind Instagram’s Recommendation Algorithm
One of Instagram’s most popular features is their explore page, where they recommend photos and videos to you. The majority of these photos and videos are from people you don’t follow, so Instagram needs to search through millions of pieces of content to generate recommendations for you.

Instagram has over 500 million daily active users, so this means billions of recommendations have to be generated every day.
Vladislav Vorotilov and Ilnur Shugaepov are two senior machine learning engineers at Meta and they wrote a fantastic blog post delving into how they built this recommendation system and how it was designed to be highly scalable.
Recommendation Systems at a High Level
All the recommendation systems you see at Twitter, Facebook, TikTok, YouTube, etc. have a similar high-level architecture.
They have a layered architecture that looks something like the following
Retrieval - Narrow down the candidates of what to show a user to thousands of potential items
First Stage Ranking - Apply a low-level ranking system to quickly rank the thousands of potential photos/videos and narrow it down to the 100 best candidates
Second Stage Ranking - Apply a heavier ML model to rank the 100 items by how likely the user is to engage with the photo/video. Pass this final ranking to the next step
Final Reranking - Filter out and downrank items based on business rules (for ex. Don’t show content from the same author again and again, etc.)
The specific details will obviously differ, but most recommendation systems use this Candidate Generation, Ranking, Final Filtering type of architecture.
Although, the format of the website can obviously change how the recommendation system works.
Hacker News primarily works based on upvotes/downvotes. I wasn’t able to find how Reddit’s recommendation system worked for hot but if you post a screenshot of how you gambled away your kid’s tuition on GameStop Options then you’ll probably get to the front page.
We’ll go through each of the layers in Instagram’s system and talk about how they work.
Retrieval
Ranking all of the billions of pieces of content uploaded to Instagram for every single user is obviously not feasible.
Therefore, the candidate generation stage uses a set of heuristics and ML models to narrow down the potential items to thousands of photos/videos.
In terms of heuristics, Instagram uses things like
Accounts you follow
Topics you’re interested in
Accounts you’ve previously engaged with
And metrics like that.
Some of these are calculated in real-time while others (for ex. topics you follow) can be pre-generated during off-peak hours and stored in cache.
In terms of ML models, Instagram makes heavy use of the Two Tower Neural Network model.
Two Tower Neural Networks
Two Tower Neural Networks is a very popular machine learning algorithm for recommender systems that Instagram uses heavily.
With a Two Tower Model, you generate embedding vectors for the user and for all the content you need to retrieve/rank. An embedding vector is just a compact representation that captures the attributes and relationships of an item in a machine-learning-friendly vector.
Once you have these embedding vectors, you can look at the similarity between a user’s embedding vector and the content’s embedding vector to predict the probability that the user will engage with the content.

One big benefit of the Two Tower approach is that both the user and item embeddings can be calculated during off-peak hours and then cached. This makes inference extremely efficient.
If you’d like to read more, Uber Engineering published an extremely detailed blog post on how they use Two Towers in the UberEats app to convince you to buy burritos at 1:30 am. I’d highly recommend giving it a skim if you’d like to delve deeper.
First Stage Ranking
After candidates are retrieved, the system needs to rank them by value to the user. This “value” is determined by how likely a user is to engage with the photo/video. Engagement is measured by whether the user likes/comments on it, shares it, watches it fully, etc.
The first stage ranker takes in thousands of candidates from the Retrieval stage and filters it down to the top 100 potential items.
To do this, Instagram again uses the Two Tower NN model. The fact that the model lets you precompute and cache embedding vectors for the user and all the content you need to rank makes it very scalable and efficient.
However, this time, the learning objective is different from the Two Tower NN of the Candidate Generation stage.
Instead, the two embedding vectors are used to generate a prediction of how the second stage ranking model will rank this piece of content. The model is used to quickly (and cheaply) gauge whether the second stage ranking model will rank this content highly.

Based on this, the top 100 posts are passed on to the second-stage ranking model.
Second Stage
Here, Instagram uses a Multi-Task Multi Label (MTML) neural network model. As the name suggests, this is an ML model that is designed to handle multiple tasks (objectives) and predict multiple labels (outcomes) simultaneously.
For recommendation systems, this means predicting different types of user engagement with a piece of content (probability a user will like, share, comment, block, etc.).
The MTML model is much heavier than the Two Towers model of the first-pass ranking. Predicting all the different types of engagement requires far more features and a deeper neural net.
Once the model generates probabilities for all the different actions a user can take (liking, commenting, sharing, etc.), these weighted and summed together to generate an Expected Value (EV) for the piece of content.
Expected Value = W_click * P(click) + W_like * P(like) – W_see_less * P(see less) + etc.The 100 pieces of content that made it to this stage of the system are ranked by their EV score.
Final Reranking
Here, Facebook applies fine-grained business rules to filter out certain types of content.
For example
Avoid sending too much content from the same author
Downrank posts/content that could be considered harmful
And so on.
For more details on the system, read the full blog post here.
How did you like this summary?Your feedback really helps me improve curation for future emails. |