How CloudFlare Processes a Million Logs per Second
We'll be talking about Kafka, the ELK stack and Clickhouse. Also, how Apple built iCloud to store billions of databases, focusing on impact, and more.
Hey Everyone!
Today we’ll be talking about
How CloudFlare Processes a Million Logs per Second
Over 20% of the internet uses CloudFlare for their CDN/DDoS protection so the company has to process a lot of traffic
Their logging system needs to ingest close to 1 million log lines every second with high availability
They use Kafka, the ELK stack and Clickhouse to build this
We’ll talk about each of these technologies and also delve into how their logging system works
Tech Snippets
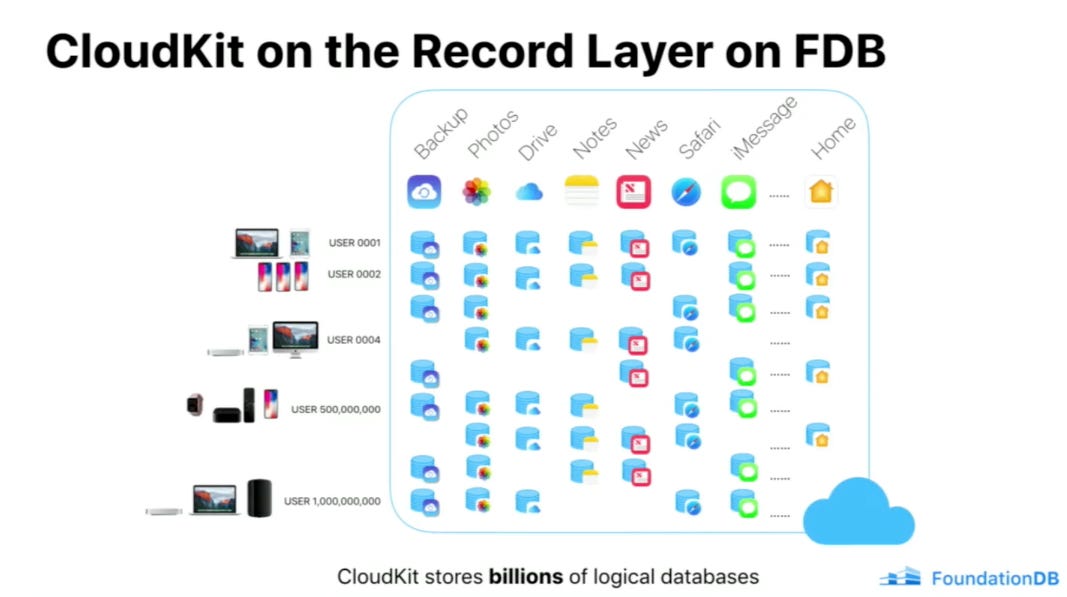
How Apple built iCloud to store billions of databases
Focusing on Impact by Andrew Bosworth (CTO of Meta)
Teach Yourself Programming in Ten Years by Peter Norvig
A Curated List of Software Architecture Related Design Patterns
Things DBs Don’t Do - But Should
How CloudFlare Processes Millions of Logs Per Second
Cloudflare is a tech company that provides services around content-delivery networks, domain registration, DDoS mitigation and much more.
You’ve probably seen one of their captcha pages when their DDoS protection service mistakenly flags you as a bot.
Or uhh, you might know them from a viral video last week where one of their employees secretly recorded them laying her off.
Over 20% of the internet uses Cloudflare for their CDN/DDoS protection, so the company obviously plays a massive role in ensuring the internet functions smoothly.
Last week, they published a really interesting blog post delving into the tech stack they use for their logging system. The system needs to ingest close to a million log lines every second with high availability.
Colin Douch is a Tech Lead on the Observability team at CloudFlare and he wrote a fantastic post on their architecture.
We’ll be summarizing it and adding some context.
CloudFlare’s Tech Stack
We’ll start by going through all the major tech choices CloudFlare made and give a brief overview of each one.
Kafka
Apache Kafka is an open source event streaming platform (you use it to transfer messages between different components in your backend).
A Kafka system consists of producers, consumers and Kafka brokers. Backend services that publish messages to Kafka are producers, services that read/ingest messages are consumers. Brokers handle the transfer and help decouple the producers from the consumers.
Benefits of Kafka include
Distributed - Kafka is built to be distributed and highly scalable. Kafka clusters can have hundreds of nodes and process millions of events per second. We previously talked about how PayPal scaled Kafka to 1.3 trillion messages per day.
Configurable - it’s highly configurable so you can tune it to meet your requirements. Maybe you want super low latency and don’t mind if some messages are dropped. Or perhaps you need messages to be delivered exactly-once and always acknowledged by the recipient
Fault Tolerant - Kafka can be configured to be extremely durable (store messages on disk and replicate them across multiple nodes) so you don’t have to worry about messages being lost
We published a deep dive on Kafka that you can read here.
Kafka Mirror Maker
If you’re a large company, you’ll have multiple data centers around the world where each might have its own Kafka cluster. Kafka MirrorMaker is an incredibly useful tool in the Kafka ecosystem that lets you replicate data between two or more Kafka clusters.
This way, you won’t get screwed if an AWS employee trips over a power cable in us-east-1.
ELK Stack
ELK (also known as the Elastic Stack) is an extremely popular stack for storing and analyzing log data.
It consists of three main open source tools:
Elasticsearch - a fast, highly scalable full-text search database that’s based on Apache Lucene. The database provides a REST API and you create documents using JSON. It uses the inverted index data structure to index all your text files and quickly search through them.
Logstash - a data processing pipeline that you can use for ingesting data from different sources, transforming it and then loading it into a database (Elasticsearch in this case). You can apply different filters for cleaning data and checking it for correctness.
Kibana - the visualization layer that sits on top of Elasticsearch. It offers a user-friendly dashboard for querying and visualizing the data stored in Elasticsearch. You can create graphs, get alerts, etc.
Clickhouse
ClickHouse is a distributed, open source database that was developed 10 years ago at Yandex (the Google of Russia) to power Metrica (a real-time analytics tool that’s similar to Google Analytics).
For some context, Yandex’s Metrica runs Clickhouse on a cluster of ~375 servers and they store over 20 trillion rows in the database (close to 20 petabytes of total data). So… it was designed with scale in mind.
Clickhouse is column-oriented with a significant emphasis on high write throughput and fast read operations. In order to minimize storage space (and enhance I/O efficiency), the database uses some clever compression techniques. It also supports a SQL-like query language to make it accessible to non-developers (BI analysts, etc.).
You can read about the architectural choices of ClickHouse here.
CloudFlare’s Logging Pipeline
In order to create logs, systems across Cloudflare use various logging libraries. These are language specific, so they use
And more. Engineers have flexibility with which logging libraries they want to use.
Cloudflare is running syslog-ng (a log daemon) on all their machines. This reads the logs and applies some rate limiting and rewriting rules (adding the name of the machine that emitted the log, the name of the data center the machine is in, etc.).
The daemon then wraps the log in a JSON wrapper and forwards it to Cloudflare’s Core data centers.
CloudFlare has two main core data centers with one in the US and another in Europe. For each machine in their backend, any generated logs are shipped to both data centers. They duplicate the data in order to achieve fault tolerance (so either data center can fail and they don’t lose logs).
In the data centers, the messages get routed to Kafka queues. The Kafka queues are kept synced across the US and Europe data centers using Kafka Mirror Maker so that full copies of all the logs are in each core data center.
Using Kafka provides several benefits
Adding Consumers - If you want to add another backend service that reads in the logs and processes them, you can do that without changing the architecture. You just have to register the backend services as a new consumer group for the logs.
Consumer outages - Kafka acts as a buffer and stores the logs for a period of several hours. If there’s an outage in one of the backend services that consumes the logs from Kafka, that service can be restarted and won’t lose any data (it’ll just pick back where it left off in Kafka). CloudFlare can tolerate up to 8 hours of total outage for any of their consumers without losing any data.
Storing Logs
For long-term storage of the logs, CloudFlare relies on two backends
ELK Stack
Clickhouse Cluster
ELK Stack
As we mentioned, ELK consists of ElasticSearch, Logstash and Kibana. Logstash is used for ingesting and transforming the logs. ElasticSearch is used for storing and retrieving them. Kibana is used for visualizing and monitoring them.
For ElasticSearch, CloudFlare has their cluster of 90 nodes split into different types
Master nodes - These act as ElasticSearch masters and coordinate insertions into the cluster.
Data nodes - These handle the actual insertion into an ElasticSearch node and storage
HTTP nodes - These handle HTTP queries for reading logs
Clickhouse
CloudFlare has a 10 node Clickhouse cluster. At the moment, it serves as an alternative interface to the same logs that the ELK stack provides. However, CloudFlare is in the process of transitioning to Clickhouse as their primary storage.
For more details, read the full blog post here.
How To Remember Concepts from Quastor Articles
We go through a ton of engineering concepts in the Quastor summaries and tech dives.
In order to help you remember these concepts for your day to day job (or job interviews), I’m creating flash cards that summarize these core concepts from all the Quastor summaries and tech dives.
The flash cards are completely editable and are meant to be integrated in a Spaced-Repetition Program (Anki) so that you can easily remember the concepts forever.
This is an additional perk for Quastor Pro members in addition to the technical deep dive articles.
Quastor Pro is only $12 a month and you should be able to expense it with your job’s learning & development budget. Here’s an email you can send to your manager. Thanks for the support!