Building a Search Index with Kafka and Elasticsearch
Hey Everyone,
Today we’ll be talking about
How computers in a distributed system synchronize their clocks
The clock synchronization problem
How computers do this using NTP (Network Time Protocol)
Brief overview of how NTP works
How DoorDash Built a Faster Indexing System for their Search feature
Using Kafka as a message queue, Apache Flink for data transformation and Elasticsearch as the search engine
Using CDC events to update the search index
Indexing bulk data that is generated by ML models
Plus some tech snippets on
How Grammarly uses Lisp
Bootstrapping a JavaScript Library to $20,000 in monthly revenue
How an Engineering Manager at Reddit judges candidates
An awesome YouTube series on How to build an Operating System
Questions? Please contact me at [email protected].
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
When you’re talking about measuring time, the gold standard is an atomic clock. Atomic clocks have an error of ~1 second in a span of 100 million years.
However, atomic clocks are way too expensive and bulky to put in every computer. Instead, individual computers contain quartz clocks which are far less accurate.
The clock drift differs on the hardware, but it’s an error of ~10 seconds per month.
When you’re dealing with a distributed system with multiple machines, it’s very important that you have some degree of clock synchronization. Having machines that are dozens of seconds apart on time makes it impossible to coordinate.
Clock skew is a measure that tells you the difference between two clocks on different machines at a certain point of time.
You can never reduce clock skew to 0, but you want to reduce clock skew as much as possible through the synchronization process.
The way clock synchronization is done is with a protocol called NTP, Network Time Protocol.
NTP works by having servers that maintain accurate measures of the time. Clients can query those servers and ask for the current time.
The client will take those answers, discard any outliers, and average the rest. It’ll use a variety of statistical techniques to get the most accurate time possible.
This is a great blog post that delves into the clock synchronization algorithm.
Here’s a list of NTP servers that you can query for the current time. It’s likely that your personal computer uses NTP to contact a time server and adjust its own personal clock.
My personal computer uses time.apple.com as its NTP time server.

It’s not possible for every computer in the world to directly query an atomic clock since there aren’t enough atomic clocks to satisfy that demand.
Therefore, there are some NTP servers in between your computer and the reference clock.
NTP arranges these servers into strata
Stratum 0 - atomic clock
Stratum 1 - synced directly with a stratum 0 device
Stratum 2 - servers that sync with stratum 1 devices
Stratum 3 - servers that sync with stratum 2 devices
And so on until stratum 15. Stratum 16 is used to indicate that a device is unsynchronized.
A computer may query multiple NTP servers, discard any outliers (in case of faults with the servers) and then average the rest.
Computers may also query the same NTP server multiple times over the course of a few minutes and then use statistics to reduce random error due to variations in network latency.
For connections through the public internet, NTP can usually maintain time to within tens of milliseconds (a millisecond is one thousandth of a second).
To learn more about NTP, watch the full lecture by Martin Kleppmann.
Quastor is a free Software Engineering newsletter that sends out summaries of technical blog posts, deep dives on interesting tech and FAANG interview questions and solutions.
Tech Snippets
Running Lisp in Production at Grammarly - Grammarly is an application that millions of people use to check their grammar for emails, essays, notes, etc.The product is built on the core grammar engine, which can process more than a thousand sentences per second.The engine is written in Common Lisp and the blog post goes into how Grammarly runs Lisp in production and some hairy bugs they faced in doing so.
Bootstrapping a JavaScript Library to $20,000 in monthly revenue - Rik is a front-end developer from The Netherlands and he started Pintura, a JavaScript Image Editor SDK.Today, over 1000+ companies use Pintura in their products, like Dropbox, Square and Convertkit.Rik did an awesome AMA on Indie Hackers where he answered questions about how he built his business.
Reddit Interview Problem: The Game of Life - Alex Golec, an engineering manager at Reddit, goes through an interview problem he used to use to screen candidates. He talks about how he evaluated candidate responses to the question and why he thinks it’s a good question.Funny enough, the question Alex goes through in this blog post is published on LeetCode. You can view it here.It might be interesting to try and solve the question yourself and see how far you can get before reading Alex’s solution (and evaluation criteria).
This is an awesome series of YouTube videos on how to build an operating system. The videos are made in a similar format to 3Blue1Brown, if you’re familiar with his mathematics content.
Building Faster Indexing with Apache Kafka and Elasticsearch
DoorDash is the largest food delivery app in the United States with more than 20 million consumers and 450 thousand restaurants.
A critical part of the DoorDash app is the search function. You can search for Scallion Pancakes and the DoorDash app will give you restaurants near you that are open and currently serving that dish.
Solving this problem at scale is quite challenging, as restaurants are constantly changing their menus, store hours, locations, etc.
You need to quickly index all of the store data to provide a great restaurant discovery feature.
Satish, Danial, and Siddharth are software engineers on DoorDash’s Search Platform team, and they wrote a great blog post about how they built a faster indexing system with Apache Kafka, Apache Flink and Elasticsearch.
Here’s a summary
DoorDash’s Problem with Search Indexing
DoorDash’s legacy indexing system was very slow, unreliable and not extensible. It took a long time for changes in store and item descriptions to be reflected in the search index. It was also very difficult to assess the indexing quality.
There were frequent complaints about mismatches in store details between the search index and the source of truth. These had to be fixed manually.
The New System
Engineers solved these problems by building a new search indexing platform with the goals of providing fast and reliable indexing while also improving search performance.
The new platform is built on a data pipeline that uses Apache Kafka as a message queue, Apache Flink for data transformation and Elasticsearch as the search engine.
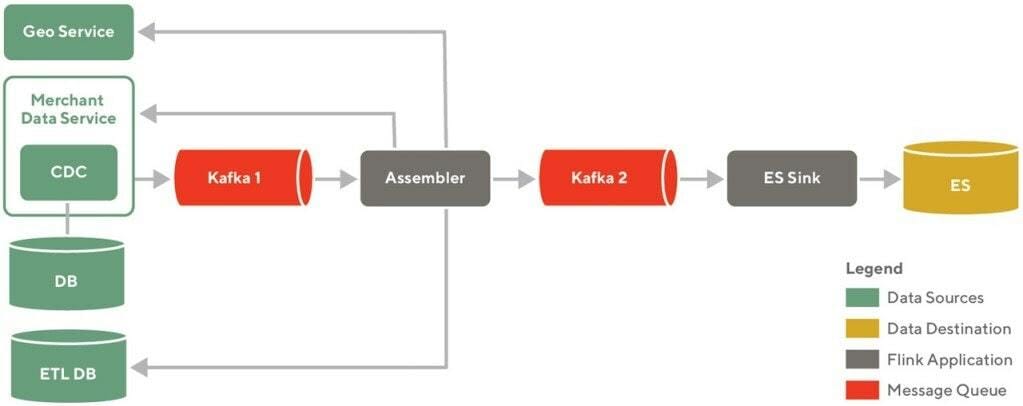
The components of the architecture are
Data sources - These are the sources of truth for the data. When CRUD operations take place on the data (changing store menu, updating store hours, etc.) then they are reflected here. DoorDash uses Postgres as the database and Snowflake as the data warehouse.
Data destination - DoorDash is using Elasticsearch here as the final data destination. It will serve as the data store and search engine.
Flink application - There are two custom Apache Flink applications in this pipeline: Assembler and ES Sink. Assembler is responsible for assembling all the data required in an Elasticsearch document. ES Sink is responsible for shaping the documents as per the schema and writing the data to the targeted Elasticsearch cluster.
Message queue - Kafka 1 and Kafka 2 are the message queue components.
This data pipeline allows for fast, incremental changes to the search index when there are changes to the restaurant data.
The changes in data sources are propagated to Flink applications using Kafka. The Flink apps implement business logic to curate the search documents and then write them to Elasticsearch.
Incremental Indexing
The indexing pipeline processes two main types of data changes.
The first type of data change is when human operators make ad hoc changes to stores or restaurant items. An example of a possible data change is a restaurant owner adding a new dish to her menu.
The second type of data change is ETL data changes that are generated from machine learning models. Things like restaurant ratings/scores or auto-generated tags are generated by machine learning models and then stored in a data warehouse.
Both of these changes need to be reflected in the search index for the best customer experience.
Here’s how DoorDash does it.
Indexing Human Operator Changes
Restaurant owners will frequently update their menus and store information. These changes need to be reflected onto the search experience as quickly as possible.
The updates are saved in data stores like Postgres.
To keep track of these updates, DoorDash search engineers rely on Change Data Capture (CDC) events.
DoorDash engineers implemented save hooks in the application to propagate change events to Kafka whenever there is a change on the underlying data store.
After receiving the Kafka events, the Assembler app will make backend calls to gather more information about the change and to create an event which it pushes to Kafka for the ES Sink app to consume.
They tested other solutions like Debezium connector, a Red Hat-developed open source project for capturing row-level changes with Postgres but they found that this strategy had too much overhead and was not performant.
Indexing ETL data
Many properties that are used in the search index are generated by ML models. Things like restaurant scores, auto-generated tags, etc.
These properties are updated in bulk, once a day. The data gets populated into tabs in DoorDash’s data warehouse after a nightly run of the respective ETL jobs.
The CDC patterns described for Human Operator Changes don’t work here because you don’t constantly have changes/updates through the day. Instead, you have one bulk update that happens once a day.
Using the CDC pattern described above would overwhelm the system when making the bulk update due to the size of the update.
Therefore, DoorDash engineers built a custom Flink source function which spreads out the ETL ingestion over a 24 hour interval so that the systems don’t get overwhelmed.
The Flink source function will periodically stream rows from an ETL table to Kafka in batches, where the batch size is chosen to ensure that the downstream systems do not get overwhelmed.
Sending documents to Elasticsearch
Once the Assembler application publishes data to Kafka, the consumer (ES Sink) will read those messages, transform them according to the specific index schema, and then send them to their appropriate index in Elasticsearch.
ES Sink utilizes Flink Elasticsearch Connector to write JSON documents to Elasticsearch.
It has rate limiting and throttling capabilities out of the box, which are essential for protecting Elasticsearch clusters when the system is under heavy write load.
Results
With the new search indexing platform, updates happen much faster. The time needed to reindex existing stores and items on the platform fell from 1 week to 2 hours.
The reliance on open source tools for the index means a lot of accessible documentation online and engineers with this expertise who can join the DoorDash team in the future.
For information on how DoorDash backfilled the search index (and more!), read the full blog post here.
Interview Question
Given a positive integer n, write a function that computes the number of trailing zeros in n!
Example
Input - 12
Output - 2
Explanation - 12! is 479001600
Input - 900
Output - 224
Explanation - 900! is a big ass number
Previous Solution
As a reminder, here’s our last question
Given two binary trees, write a function that checks if they are the same or not.
Two binary trees are considered the same if they are structurally identical and corresponding nodes have the same values.
Solution
We can solve this question with recursion.
We’re given two tree nodes and we first check if either of them are null.
If both of them are null, then we can return True since any two empty trees are equivalent.
If either of them are null (but not both), then we can return False since an empty tree is never equivalent to a non-empty tree.
Now, we can check if the root node of both trees are the same.
If they are the same, then we’ll check if the right subtree of the first tree is equivalent to the right subtree of the second tree. We’ll do this by calling our function recursively.
We’ll check the same for the left subtrees.
If the subtrees are equivalent then we can return True.
Here’s the Python 3 code.

.