Browser-side Storage Explained
A deep dive into the tools available for Browser-side storage. Plus, things you should know about Postgres. Also, a tool to make GPU programming easier.
Hey Everyone,
Today we’ll be talking about
APIs that you can use for browser-side storage
We talk about Web Storage, IndexedDB, Cookies, AppCache, WebSQL and more!
Things you should know about Postgres
Some of the top comments from a discussion on r/PostgreSQL on “what you wish you knew about Postgres before building your app”
Triton, an open source Python-like language for GPU programming
We also have a solution to our last Coding Interview question on Palindromes and a new interview question from Microsoft.
Don’t forget to move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from [email protected]” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
The Ultimate Guide to Browser-Side Storage
If you need to store data with guaranteed persistence, then you’ll need some type of database in your backend.
If you don’t need a persistence guarantee, then sometimes storing data client-side (in a user’s browser), is a more viable option. Other times, it may be essential to use browser-side storage.
The article linked is a comprehensive guide to your choices for browser-side storage.
It talks about
Current Options - APIs you can use today in all modern and most older browsers
Future Options - Experimental APIs which should be stable within a few years
Past Options - Deprecated APIs you should avoid
Here’s the summary
Current Options
Web Storage
The Web Storage API allows you to store key/value pairs.
You can have localStorage for persistent data and sessionStorage for temporary session data.
The browser limits each domain to 5 megabytes and read/write operations are synchronous, so they can delay other JavaScript processes.
Web Storage is also string-only, so you may have to serialize/deseralize your data.
Additionally, saving large datasets can affect page performance (because operations are synchronous).
IndexedDB
The IndexedDB API is meant for storing large amounts of structured data.
The data storage limits are quite large (if they exist at all), but the various browsers handle limits and data eviction differently.
IndexedDB gives you a NoSQL-like key/value database where your values can be complex structured objects.
Each IndexedDB is unique to an origin, so it cannot be accessed by any other origin.
The API uses database indexes to enable fast searches of your data (hence the name IndexedDB).
The API is mostly asynchronous (you have to pass callback functions) and it is built on a transactional database model. Transactions are atomic but IndexedDB does not provide transaction isolation guarantees (for concurrent transactions in multiple tabs).
The main disadvantage of IndexedDB is that the API is quite poor.
However, you can use a wrapper like idb to make it usable (which is what the majority of developers do).
Cookies
Strictly speaking, cookies are not a client-side storage option since both the browser and the backend server can modify a cookie.
But, cookies are one of the most popular browser-side storage option and they’re essential for any system that maintains server/browser state such as logging on.
A domain can store no more than 20 named cookies with a maximum string of 4 kilobytes in each.
This is a restrictive 80 kilobyte limit, but that’s because every HTTP request and response sends the cookie data.
However, some disadvantages with cookies (other than the limited storage space) include
Require string serialization and deserialization
Browsers and plugins can block cookies
Legal requirements (you may need an opt-in or warning)
Cache API
The Cache API stores HTTP request and response objects.
It’s primarily used for PWAs to cache network responses so apps can serve cached responses when they’re offline.
The Cache API is not really practical for storing other types of data.
Chrome-based browsers typically permit 100 megabytes per domain, but Safari limits it to 50 megabytes and evicts the cache after 14 days.
Future Options
File System Access API
The new File System Access API allows a browser to read, write, update and delete from your local file system when granted permission to a specific file or directory.
The API provides a FileSytemHandle interface that represents a file or directory entry and you work with FileSystemFileHandle or FileSystemDirectoryHandle objects that implement that interface.
One example of where this API is immensely useful is with apps like Google Docs. Right now, web-based text editors require you to upload your files, edit them, and then download the updated version.
With the File System Access API, your files could automatically be synced locally (and in the cloud) through a web-based text editor.
File and Directory Entries API
The File and Directory Entries API provides a domain-specific virtual local file system where a web app can read and write files without having to request user permission.
Support is available in most browsers, but it’s not on the Web Standards track so you may want to avoid this option for now.
Past Options
WebSQL
WebSQL brought SQL-like database storage to the browser, allowing anyone who knew SQL to use it.
However, Chrome and Safari offered varying inconsistent implementations of WebSQL, while Mozilla and Microsoft opposed it in favor of IndexedDB.
The API was deprecated in 2010.
AppCache
AppCache is the predecessor to the Cache API.
It attempted to specify caching behavior in a plain-text manifest file, but there were many issues and gotchas around AppCache that would break your website.
A great article that goes over the issues with AppCache is the aptly titled Application Cache is a Douchebag by Jake Archibald.
Tech Snippets
How Etsy built their bidding system for Etsy Ads - Etsy Ads is an advertising platform for Etsy sellers who want to advertise their goods across Etsy’s website and mobile app. You place bids in Etsy’s real-time auction for ad spots on Etsy’s web page.Etsy discusses their contextual bidding algorithm in this blog post, which uses machine learning to automatically determine the amount a seller should bid for an ad spot to maximize their earnings.
GistPad, a VSCode extension for editing GitHub Gists - If you frequently use GitHub Gists to manage code snippets, scripts, notes, etc. then GistPad is a great VSCode extension that lets you create and edit your Gists as if they were stored locally.You can also view other people’s Gists within VSCode and fork or star them.
Triton, an open source Python-like language for GPU programming - When you’re training a neural network, it’s essential to make use of a GPU to parallelize your computations.This usually means using something like CUDA, but GPU programming can be incredibly difficult.OpenAI is now releasing Triton, an open source Python-like language that allows you to write highly efficient GPU code with no CUDA experience.With Triton, you can do something like write a function for matrix multiplication (parallelized) with just ~25 lines of Python code and achieve performance comparable with what you’d get from writing in CUDA.Triton compiles your Python GPU code into PTX instructions.

What you should know about Postgres
There was an interesting discussion on /r/PostgreSQL on things developers wished they knew about Postgres before building their app.
Here are some of the top comments
For tables with dynamic data, you should always have two timestampz (timestamp with timezone) fields with created_at and updated_at columns with the default now() value for created_at.
These fields will come in handy in the future when you’re doing analytics and reporting. It’s also much more of a hassle to add them in later on versus starting your table with them.
Start with two database sessions, a read only session and a read/write session available to your app. Adding a read replica is easy to do in the beginning, but gets more difficult to add later (in terms of refactoring your codebase).
It’s important to remember that adding a read replica will create some issues with consistency (your read replica state may be behind the main database).
If you’re moving to Postgres from MySQL, then you should know about
Postgres’ amazing extension ecosystem. Things like TimescaleDB (Postgres for time-series data) and PostGIS (adds support for spatial data - data that includes location information) are incredibly useful and often better solutions than databases solely dedicated for those purposes.
The default Transaction Isolation Level (the I in ACID) differs from MySQL.
For columns where you intend to store a Boolean value, consider using a nullable date/time field instead. Oftentimes, you’ll need to know when a Boolean field was set, not just whether it is true or false. It’s less work to just use that column type from the outset.
Interview Question
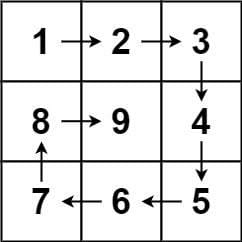
Given a positive integer i, generate an n x n matrix filled with elements from 1 to i^2 in spiral order.
Example
Input: i = 3
Output: [[1,2,3],[8,9,4],[7,6,5]]
We’ll send the solution in our next email, so make sure you move our emails to primary, so you don’t miss them!
Gmail users—move us to your primary inbox
On your phone? Hit the 3 dots at the top right corner, click "Move to" then "Primary"
On desktop? Back out of this email then drag and drop this email into the "Primary" tab near the top left of your screen
A pop-up will ask you “Do you want to do this for future messages from [email protected]” - please select yes
Apple mail users—tap on our email address at the top of this email (next to "From:" on mobile) and click “Add to VIPs”
Previous Solution
As a reminder, here’s our last question
You are given a string s which consists of lowercase or uppercase letters.
Return the length of the longest palindrome that can be built with those letters.
The letters are case sensitive. “Aa” is not considered a palindrome.
Solution
Remember that the order of the characters in s does not matter for our palindrome.
We just need to reuse the characters in s in a case-sensitive way.
A palindrome consists of letters with equal pairs, plus an optional unique center (without a pair).
Looking at the palindrome racecar, every letter has a pair except for the unique center (the letter e).
On the other hand, we can have a palindrome like abccba where there is no unique center.
Therefore, we can solve this question by first counting the number of occurrences for all the letters in s.
We can use a hash table (python dictionary) to do this in linear time.
Then, we iterate through all the letters in s and their counts.
If the count for a letter is even, then we can just add all of the letters to our palindrome. Each letter will have a pair since there are an even number of letters.
If the count for a letter is odd, then we can ignore one of those letters and add the rest to our palindrome.
So, if there are 7 occurrences of the letter n in s, then we can add 6 n’s to our palindrome since they’ll all have matches.
If we don’t have a unique center yet, then we can add in the remaining letter as our unique center.
After iterating through all the letters and their counts, we can return the length of our hash table.
Here’s the Python 3 code.
