The Architecture of Facebook's Distributed Message Queue
The engineering behind Facebook's Ordered Queueing Service and how it implements At Least Once delivery.
Hey Everyone!
Today we’ll be talking about
The Architecture of Facebook’s Distributed Message Queue
How Facebook Ordered Queueing Service works
Implementing Enqueue and Dequeue on sharded MySQL
Guaranteeing At Least Once delivery with Ack/Nack
Tech Snippets
How the Typescript Compiler Works
Functional Programming at DoorDash
Internals of Go's New Fuzzing System
ML Education at Uber
The Architecture of Facebook’s Distributed Message Queue
Facebook uses thousands of distributed systems and microservices to power their ecosystem. In order to communicate with each other, these microservices rely on a message queue.
Facebook Ordered Queueing Service (FOQS) is an internal Facebook tool that fills that role. FOQS is a horizontally scalable, persistent, distributed priority queue that’s built on top of sharded MySQL.
Akshay Nanavati and Girish Joshi are two software engineers at Facebook, and they wrote a great blog post on how FOQS works and the architecture behind it.
Here’s a Summary
FOQs Use Cases
FOQS is a general purpose priority queue so hundreds of different services across the Facebook stack rely on it to pass messages. Facebook’s video encoding service, language translation technologies and notification services are a few examples.
Producer services will enqueue items on to FOQS to be processed. These items can have a priority and also a delay (if the item processing needs to be deferred). The item will have a topic, where each topic is a separate priority queue.
Consumer services can dequeue items from a certain topic and process them. If the processing succeeds, they send an “ack” message back to FOQS. If the processing fails, then they send a “nack” message back and the items will be redelivered from the priority queue at a later time.
Building a Distributed Priority Queue
FOQS is organized into namespaces where each namespace has many topics and each topic has many items.
Namespaces provide a way to separate all the different services/use-cases that are using FOQS. Each namespace will have many (thousands) of topics, where each topic represents a single priority queue.
Clients will enqueue and dequeue items to a topic where an item represents a message with some user specified data.
Each item will have fields for the namespace, topic, priority (a 32 bit integer), payload (an immutable 10 kilobyte blob), metadata, delivery delay (how long until the item can be dequeued) and a few other fields.
FOQS provides an API that consists of the following operations
Enqueue - Add an item to FOQS.
Dequeue - Accepts a topic and a number where the number signifies how many items to return from the topic. Items are returned based on priority and delivery delay.
Ack - Sends a message that the dequeued item was successfully processed, so it doesn’t need to be delivered again.
Nack - Sends a message that the dequeued item needs to be redelivered because client processing failed. The processing can be deferred, allowing clients to leverage exponential backoff to give enough of a “cooling-off” period of buffer.
GetActiveTopics - returns a list of the topics that have items
We’ll go through how these operations work under the hood.
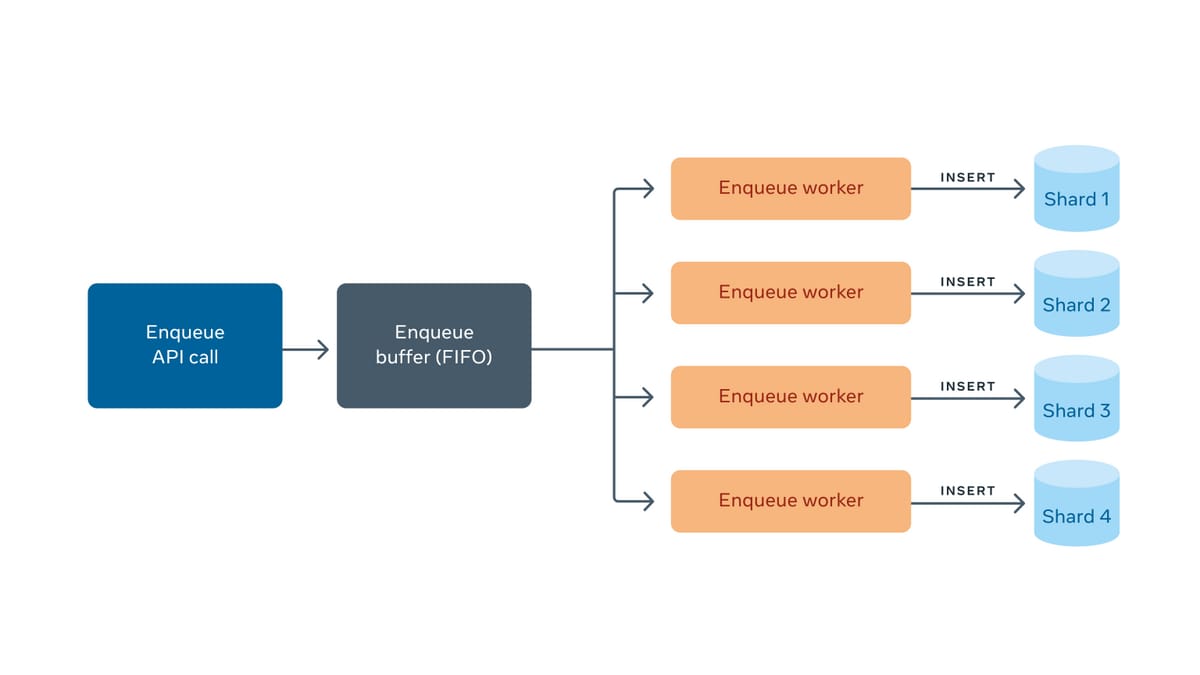
Enqueue
When a client enqueues an item to FOQS, the request gets put on an Enqueue Buffer and FOQS returns a promise back to the client.
FOQS is built on top of sharded MySQL and each shard has a corresponding worker node. The workers are reading items from the Enqueue Buffer and inserting them into their MySQL shard where one database row corresponds to one item.
Once the row insertion is complete, the promise is fulfilled and an enqueue response is sent back to the client. The response contains a unique string that contains the MySQL shard’s ID and a 64-bit primary key (that identifies the item in its shard).
FOQS uses a circuit breaker design pattern to avoid sending items to unhealthy MySQL shards. Health is defined by slow queries or error rate; if either of those cross a threshold then the corresponding worker will stop accepting more work until it’s healthy.
Dequeue
The dequeue API accepts a collection of (topic, count) pairs where count represents the number of items to return from the topic. The items returned are ordered by priority.
Since each topic is sharded, each topic host will need to run a reduce operation across all the MySQL shards for that topic to find the highest priority items and select those.
To optimize this, FOQS has a data structure called the Prefetch Buffer that works in the background and fetches the highest priority items across all the shards.
Each shard has an in-memory index of the primary keys of items that are ready to be delivered on the shard, sorted by priority. The Prefetch Buffer will build its own priority queue from these indexes using a K-way merge.
The dequeue API just has to read items out of the Prefetch Buffer and return them to the client.

Ack/Nack
FOQS supports at least once delivery and that’s implemented using Ack/Nack (short for Acknowledged or Not Acknowledged). An ack signifies that the dequeued item was successfully processed by the consumer, so the message doesn’t need to be delivered again. A nack signifies that the item should be redelivered because the consumer client failed to process it.
When an item is enqueued, FOQS allows the client to specify a lease duration. When that item gets dequeued, the lease begins. If the item is not acked or nacked within the lease duration, it is assumed to have failed (nacked) and it’s made available for redelivery, so that the at least once guarantee is met.
When an item succeeds/fails, the client sends the ack/nack request to FOQS. The shard ID is contained in the item ID, so the FOQS client uses that ID to locate the specific FOQS shard that manages that item.
The ack/nack gets sent to a shard-specific in-memory buffer, there are separate buffers for acks vs. nacks. A worker will pull items from the ack buffer and delete those rows from the MySQL shard. Similarly, a worker will pull items from the nack buffer and update that row with a new deliver_after time so the item gets redelivered.

For more details, you can read the full blog post here.
How did you like this summary?Your feedback really helps me improve curation for future emails. |
The Architecture of Volvo’s DevOps Monitoring Platform
Volvo recently redesigned their DevOps monitoring systems and processes. They needed a tool to observe all of their IT components, check metrics and send alerts for any incidents.
Their goals were to make it self-serve for developers, embrace a data-driven approach to monitoring and make it transparent.
Some of the technologies they used were InfluxDB’s time series platform at the core, Grafana for charting, alerts, etc, Kafka for messaging and more..

sponsored
Tech Snippets
How the Typescript Compiler Works - Orta Therox is an engineer at Microsoft working on TypeScript. He gave a great talk where he delves into how the TypeScript compiler works. He goes through the full pipeline of TypeScript reading a typescript file, manipulating it in memory and then writing a javascript file. You can view the slides here.
Functional Programming at DoorDash - In 2020, DoorDash transitioned from a Python monolith to Kotlin microservices. In order to write cleaner code, they’ve adopted the paradigm of functional programming with Kotlin. This is a great article from DoorDash engineering that explains some of the basics of functional programming, compare it with imperative, go through some pros/cons and talk about how they’re writing it in Kotlin.
Internals of Go's new fuzzing system - Go has great built-in support for testing and one of the features is fuzz testing (fuzzing) where you can submit a fuzz test where you write code to check if a response is correct for a given input. Then, random data is run against your tests to find vulnerabilities. This article gives a great overview of how this system works.
ML Education at Uber - As companies start relying more and more on machine learning, it’s essential to train employees on the new tools and techniques being used. Uber has a program for teaching ML education to Uber Tech employees and they wrote a great blog post giving an overview of how the program works. They talk about the curriculum and the design principles that they’re trying to teach Uber engineers.
Interview Question
The variance of a string is defined as the largest difference between the number of occurrences of any 2 characters present in the string.
The string "aaabbc" has a variance of 2 since a appears 3 times and c appears 1.
Note the two characters may or may not be the same. The string "a" has a variance of 0.
Given a string s consisting of lowercase English letters only, return the largest variance possible among all substrings of s.
Previous Question
As a reminder, here’s our last question
You are given the root node of a Binary Search Tree and a L and R value.
Return the sum of values of all the nodes with a value between L and R inclusive.
The Binary Search Tree will have unique values.
Solution
We can solve this by utilizing a Depth-First Search.
We run a DFS on the Binary Search Tree and keep a running tally of the sum of the nodes in the tree (if the value of the node is between L and R).
Additionally, we can “prune” the tree by avoiding DFS on nodes that we know will be out of the L and R range based off the properties of a Binary Search Tree.
If node.value <= L then we don’t have to run the DFS on node.left.
If node.value >= R then we don’t have to run the DFS on node.right.
We can return the sum when we're done searching.
